
Percentiles don’t work: Analyzing the distribution of response times for web services
Adrian Cockcroft
JANUARY 29, 2023
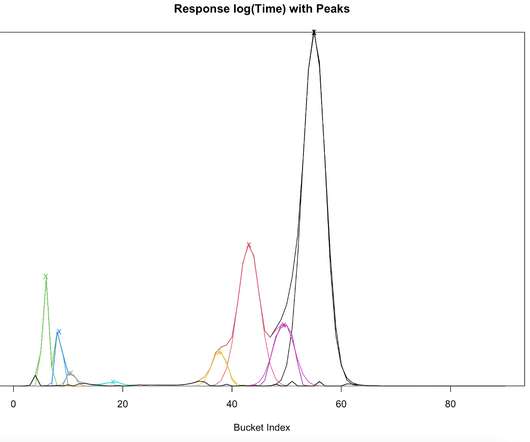
The mean and percentile measurements hide this structure, but the rest of this post will show how the structure can be measured and analyzed so that you can figure out a useful model of your system, understand what is driving the long tail of latencies and come up with better SLAs and measures of capacity.














Let's personalize your content