
So many bad takes?—?What is there to learn from the Prime Video microservices to monolith story
Adrian Cockcroft
MAY 6, 2023
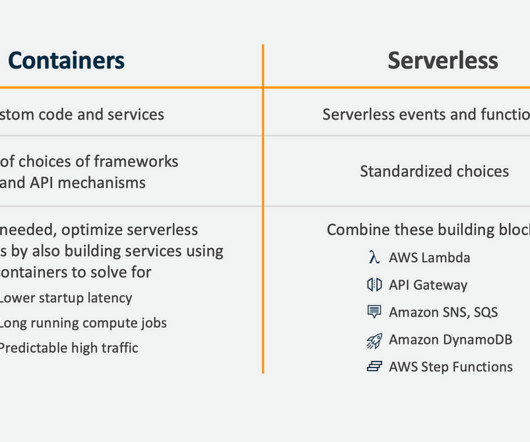
I don’t advocate “Serverless Only”, and I recommended that if you need sustained high traffic, low latency and higher efficiency, then you should re-implement your rapid prototype as a continuously running autoscaled container, as part of a larger serverless event driven architecture, which is what they did.









Let's personalize your content