
Orchestrating Data/ML Workflows at Scale With Netflix Maestro
The Netflix TechBlog
OCTOBER 18, 2022
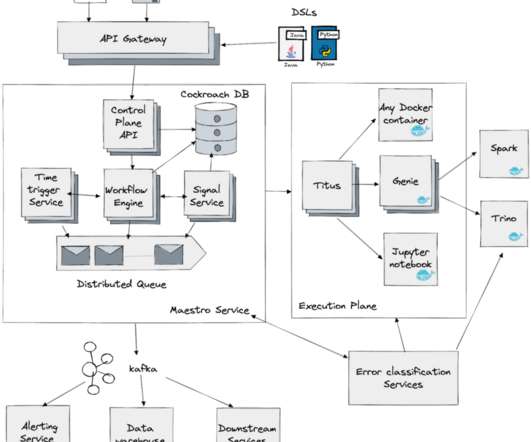
Meson was based on a single leader architecture with high availability. Therefore, the orchestrator has to manage a workflow consisting of hundreds of thousands of jobs in a performant way, which is also quite challenging. Figure 1 shows the high-level architecture. With the high growth of workflows in the past few years?












Let's personalize your content