

In-Stream Big Data Processing
Highly Scalable
AUGUST 20, 2013
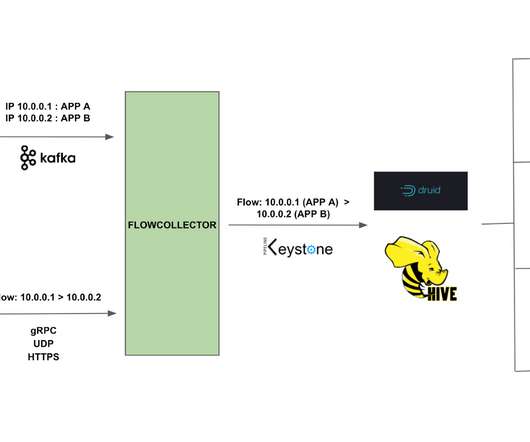
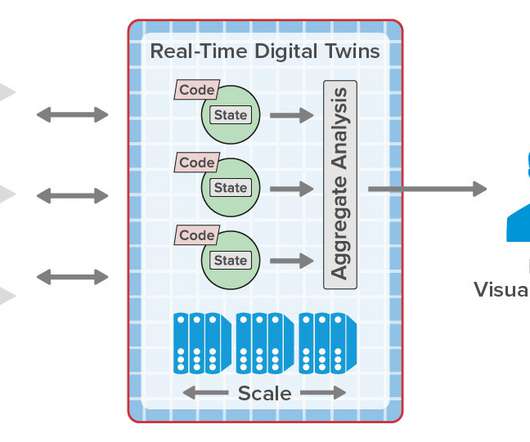
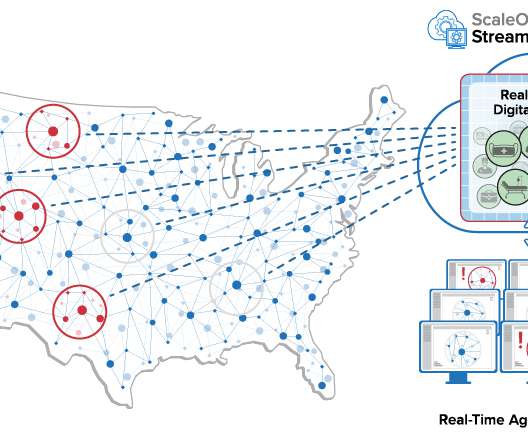
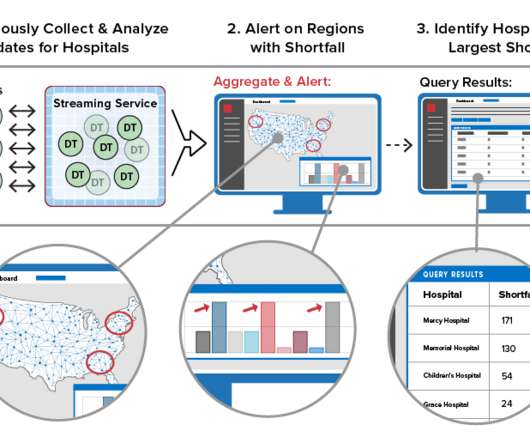
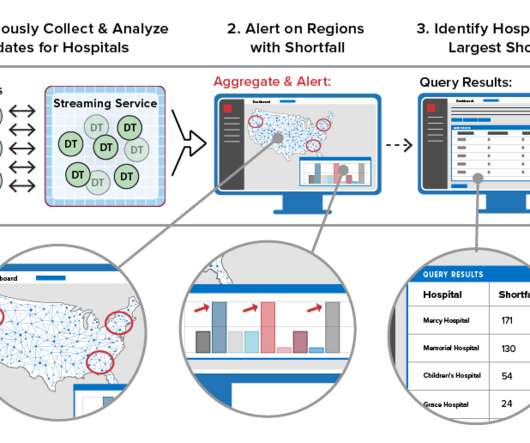
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the Big Data community quite a long time ago. In addition, we survey the current and emerging technologies and provide a few implementation tips. The article is based on a research project developed at Grid Dynamics Labs.




























Let's personalize your content