

Building Netflix’s Distributed Tracing Infrastructure
The Netflix TechBlog
OCTOBER 19, 2020
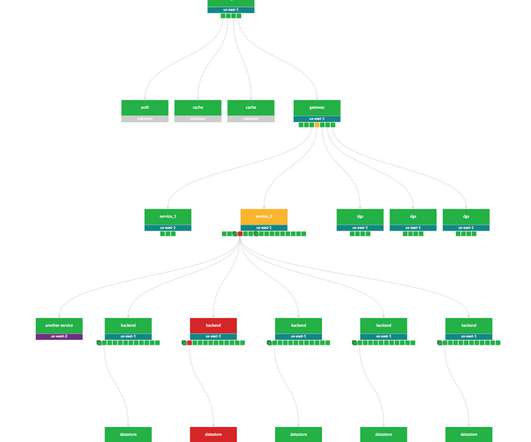
Our distributed tracing infrastructure is grouped into three sections: tracer library instrumentation, stream processing, and storage. This was the most important question we considered when building our infrastructure because data sampling policy dictates the amount of traces that are recorded, transported, and stored.















Let's personalize your content