

Implementing service-level objectives to improve software quality
Dynatrace
DECEMBER 27, 2022
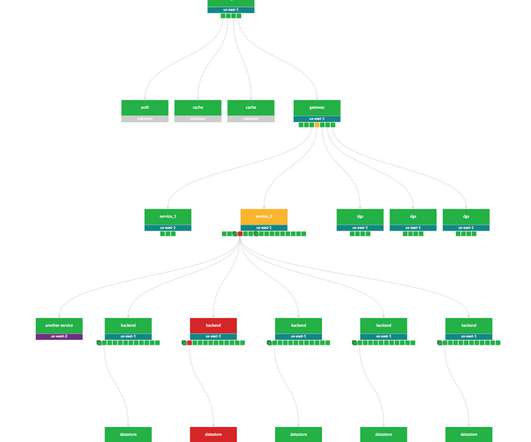
Instead, they can ensure that services comport with the pre-established benchmarks. In what follows, we explore some of these best practices and guidance for implementing service-level objectives in your monitored environment. Latency is the time that it takes a request to be served. SLOs improve software quality. Reliability.

















Let's personalize your content