

Site reliability done right: 5 SRE best practices that deliver on business objectives
Dynatrace
MAY 31, 2023
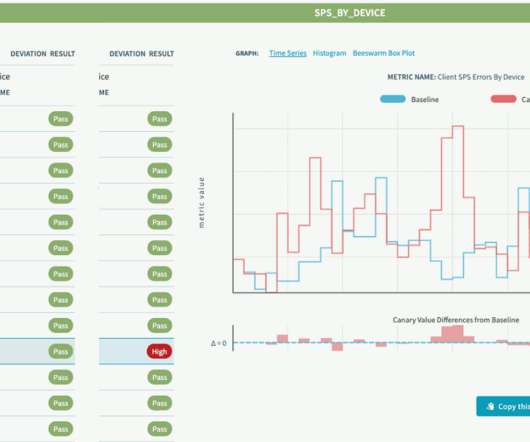
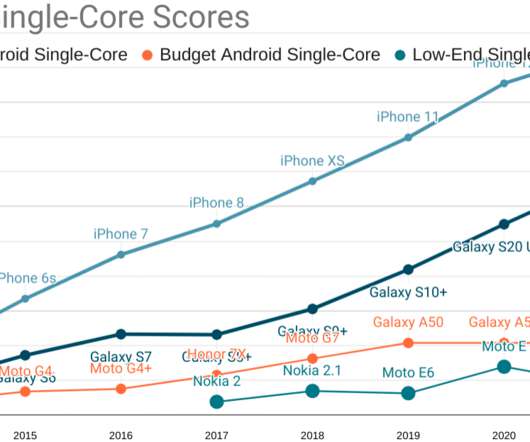
As a result, site reliability has emerged as a critical success metric for many organizations. Uptime Institute’s 2022 Outage Analysis report found that over 60% of system outages resulted in at least $100,000 in total losses, up from 39% in 2019. More than one in seven outages cost more than $1 million. availability.
















Let's personalize your content