

Site reliability done right: 5 SRE best practices that deliver on business objectives
Dynatrace
MAY 31, 2023
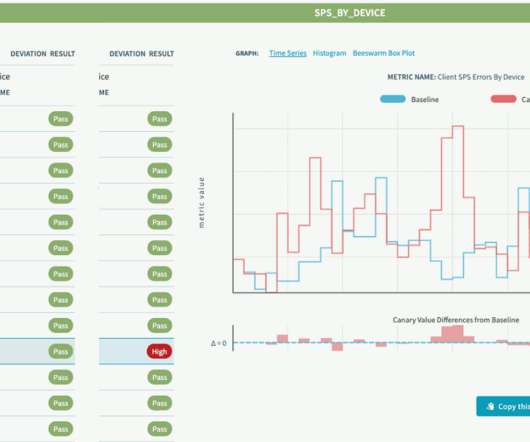
As a result, site reliability has emerged as a critical success metric for many organizations. The practice uses continuous monitoring and high levels of automation in close collaboration with agile development teams to ensure applications are highly available and perform without friction. Service-level objectives (SLOs). availability.

















Let's personalize your content