
Percentiles don’t work: Analyzing the distribution of response times for web services
Adrian Cockcroft
JANUARY 29, 2023
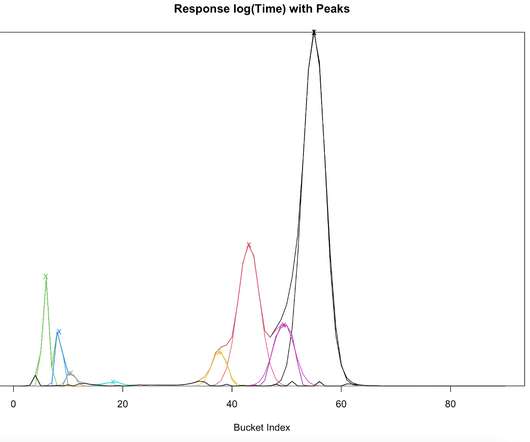
There is no way to model how much more traffic you can send to that system before it exceeds it’s SLA. I presented this analysis of response time distributions talk in 2016 — at Microxchg in Berlin ( video ). Mu is the mean of each component, the latency. I’ve been thinking about this for a long time.













Let's personalize your content