

Site reliability engineering: 5 things you need to know
Dynatrace
FEBRUARY 4, 2021
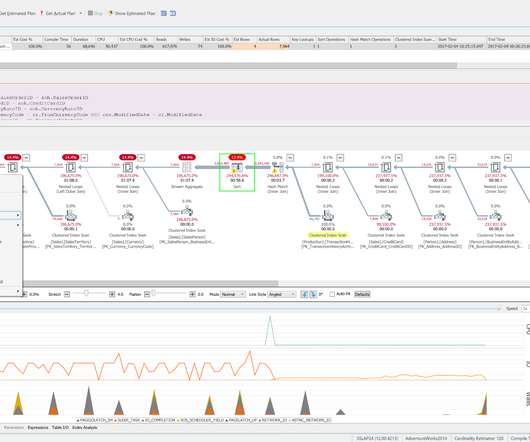
As a discipline, SRE focuses on improving software system reliability across key categories including availability, performance, latency, efficiency, capacity, and incident response. ” According to Google, “SRE is what you get when you treat operations as a software problem.” Dynatrace can help.












Let's personalize your content