

Friends don't let friends build data pipelines
Abhishek Tiwari
JULY 12, 2018
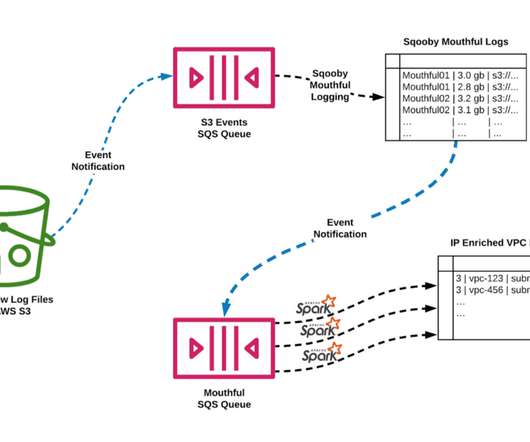
Unfortunately, building data pipelines remains a daunting, time-consuming, and costly activity. Not everyone is operating at Netflix or Spotify scale data engineering function. Often companies underestimate the necessary effort and cost involved to build and maintain data pipelines.








Let's personalize your content