

Incremental Processing using Netflix Maestro and Apache Iceberg
The Netflix TechBlog
NOVEMBER 20, 2023
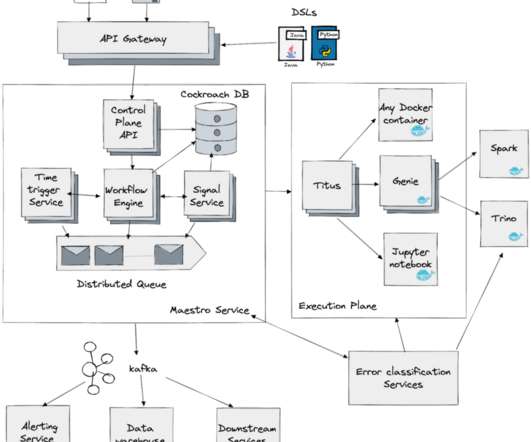
It also improves the engineering productivity by simplifying the existing pipelines and unlocking the new patterns. We will show how we are building a clean and efficient incremental processing solution (IPS) by using Netflix Maestro and Apache Iceberg. Users configure the workflow to read the data in a window (e.g.









Let's personalize your content