
Hashnode Creates Scalable Feed Architecture on AWS with Step Functions, EventBridge and Redis
InfoQ
MARCH 15, 2024
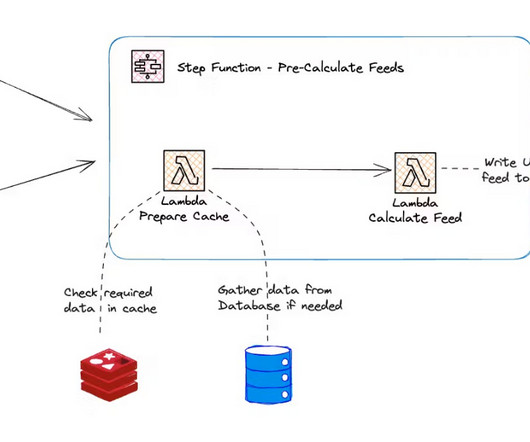
Hashnode created a scalable event-driven architecture (EDA) for composing feed data for thousands of users. The company used serverless services on AWS, including Lambda, Step Functions, EventBridge, and Redis Cache. The solution leverages Step Functions' distributed maps feature that enables high-concurrency processing.
















Let's personalize your content