
Hyper Scale VPC Flow Logs enrichment to provide Network Insight
The Netflix TechBlog
MAY 26, 2020
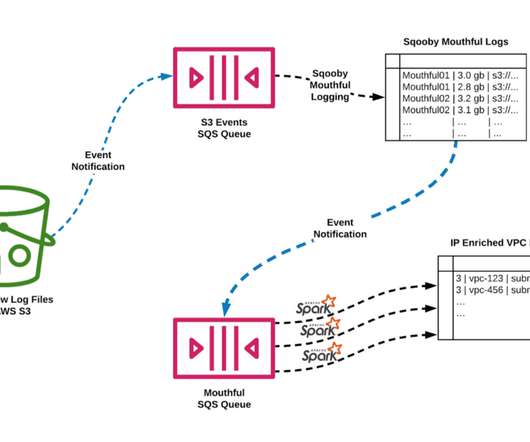
Without having network visibility, it’s not possible to improve our reliability, security and capacity posture. Network Availability: The expected continued growth of our ecosystem makes it difficult to understand our network bottlenecks and potential limits we may be reaching. 43416 5001 52.213.180.42










Let's personalize your content