
Auto-Diagnosis and Remediation in Netflix Data Platform
The Netflix TechBlog
JANUARY 13, 2022
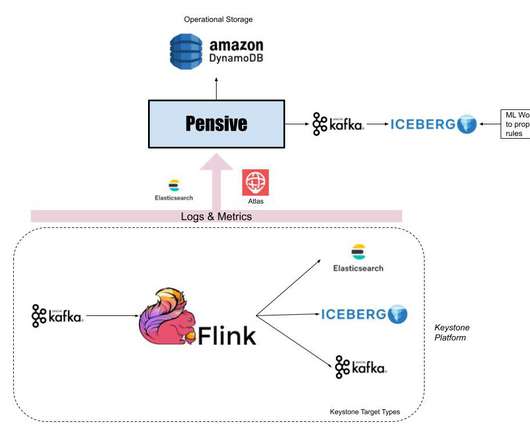
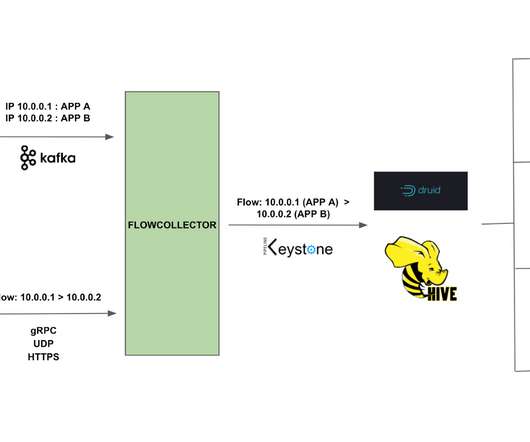
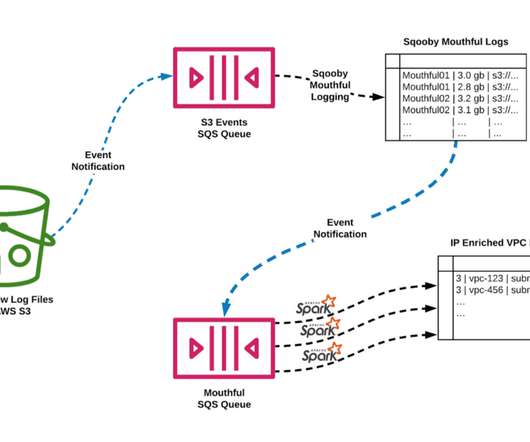
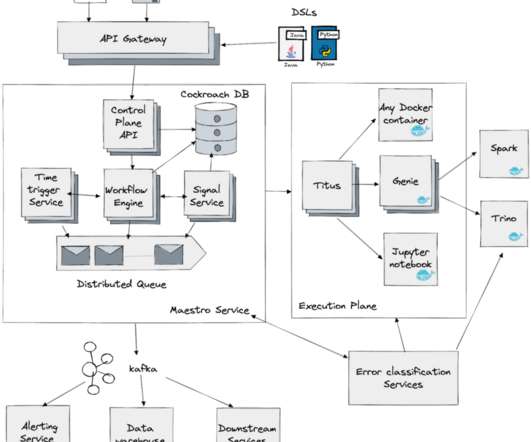
This blog will explore these two systems and how they perform auto-diagnosis and remediation across our Big Data Platform and Real-time infrastructure. Since the data platform manages keystone pipelines, users expect platform issues to be detected and remediated by the Keystone team without any involvement from their end.












Let's personalize your content