

Why applying chaos engineering to data-intensive applications matters
Dynatrace
MAY 23, 2024
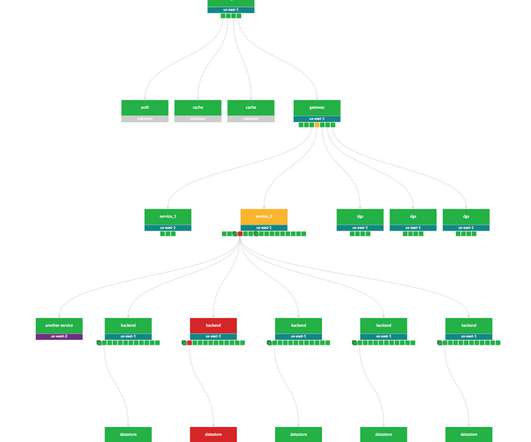
ShuffleBench i s a benchmarking tool for evaluating the performance of modern stream processing frameworks. Stream processing systems, designed for continuous, low-latency processing, demand swift recovery mechanisms to tolerate and mitigate failures effectively. This significantly increases event latency.

















Let's personalize your content