
Scaling Media Machine Learning at Netflix
The Netflix TechBlog
FEBRUARY 13, 2023
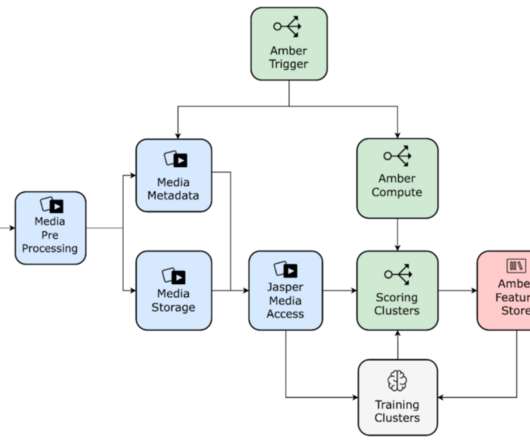
We will then present a case study of using these components in order to optimize, scale, and solidify an existing pipeline. Media Feature Storage: Amber Storage Media feature computation tends to be expensive and time-consuming. We accomplish this by paving the path to: Accessing and processing media data (e.g.









Let's personalize your content