
Cloudburst: stateful functions-as-a-service
The Morning Paper
FEBRUARY 6, 2020
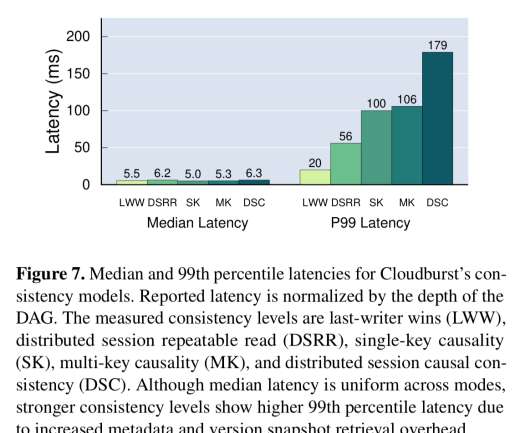
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).












Let's personalize your content