

Setting Up and Deploying PostgreSQL for High Availability
Percona
JULY 7, 2023
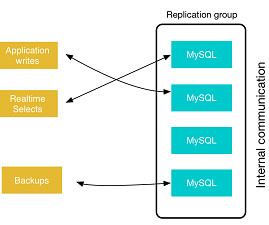
Such a proxy acts as the traffic cop between the applications and the database servers. You can get more details — and view actual architectures — at the Percona Highly Available PostgreSQL web page or by downloading our white paper, Percona Distribution for PostgreSQL: High Availability With Streaming Replication.









Let's personalize your content