
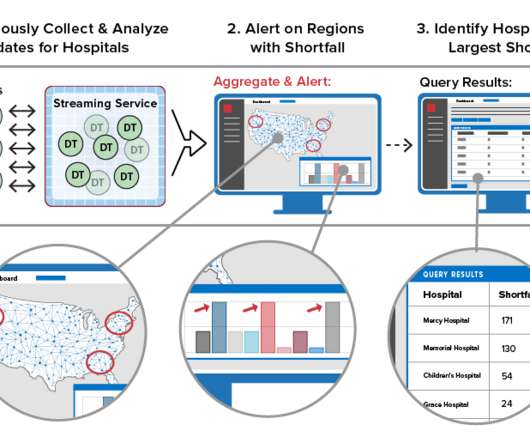
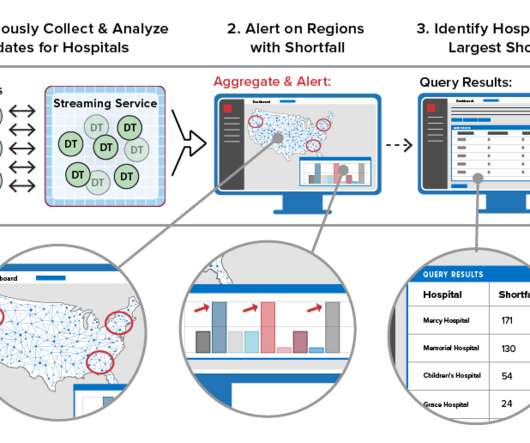
Using Real-Time Digital Twins for Aggregate Analytics
ScaleOut Software
JUNE 15, 2020
Instead, most applications just sift through the telemetry for patterns that might indicate exceptional conditions and forward the bulk of incoming messages to a data lake for offline scrubbing with a big data tool such as Spark. Maintain State Information for Each Data Source.








Let's personalize your content