

Bandwidth or Latency: When to Optimise for Which
CSS Wizardry
JANUARY 31, 2019
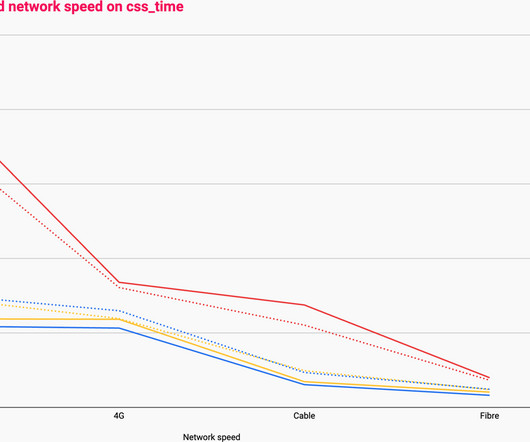
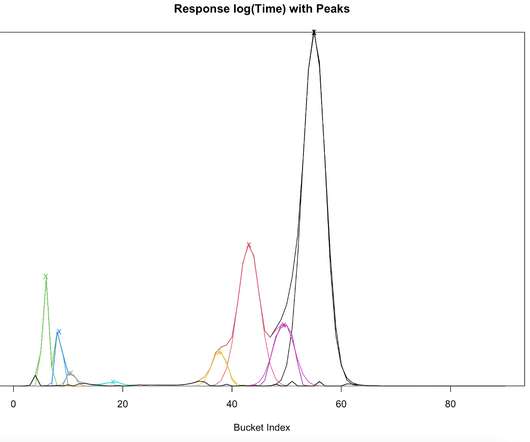
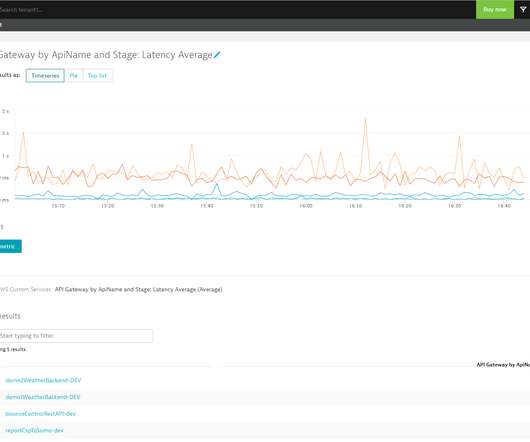
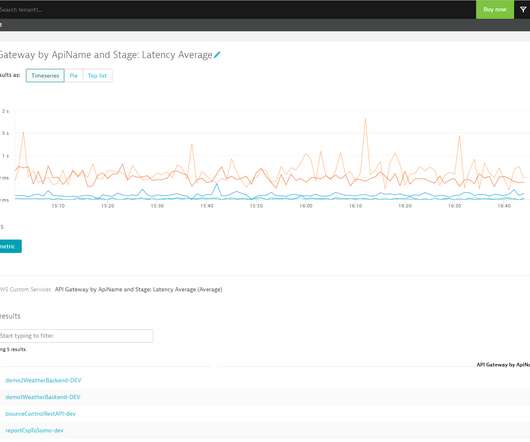
When it comes to network performance, there are two main limiting factors that will slow you down: bandwidth and latency. Latency is defined as…. how long it takes for a bit of data to travel across the network from one node or endpoint to another. and reduction in latency. and reduction in latency.










































Let's personalize your content