


This article is the third installment in a series on NULL complexities. In Part 1 I covered the meaning of the NULL marker and how it behaves in comparisons. In Part 2 I described the NULL treatment inconsistencies in different language elements. This month I describe powerful standard NULL handling features that have yet to make it to T-SQL, and the workarounds that people currently use.
I’ll continue using the sample database TSQLV5 like last month in some of my examples. You can find the script that creates and populates this database here, and its ER diagram here.
DISTINCT predicate
In Part 1 in the series I explained how NULLs behave in comparisons and the complexities around the three-valued predicate logic that SQL and T-SQL employ. Consider the following predicate:
If any predicand is NULL — including when both are NULL — the outcome of this predicate is the logical value UNKNOWN. With the exception of the IS NULL and IS NOT NULL operators, the same applies to all other operators, including different than (<>):
Often in practice you want NULLs to behave just like non-NULL values for comparison purposes. That’s especially the case when you use them to represent missing but inapplicable values. The standard has a solution for this need in the form of a feature called the DISTINCT predicate, which uses the following form:
Instead of using equality or inequality semantics, this predicate uses distinctness-based semantics when comparing predicands. As an alternative to an equality operator (=), you would use the following form to get a TRUE when the two predicands are the same, including when both are NULLs, and a FALSE when they are not, including when one is NULL and the other isn’t:
As an alternative to a different than operator (<>), you would use the following form to get a TRUE when the two predicands are different, including when one is NULL and the other isn’t, and a FALSE when they are the same, including when both are NULL:
Let’s apply the DISTINCT predicate to the examples we used in Part 1 in the series. Recall that you needed to write a query that given an input parameter @dt returns orders that were shipped on the input date if it’s non-NULL, or that were not shipped at all if the input is NULL. According to the standard, you would use the following code with the DISTINCT predicate to handle this need:
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE shippeddate IS NOT DISTINCT FROM @dt;
For now, recall from Part 1 that you can use a combination of the EXISTS predicate and the INTERSECT operator as a SARGable workaround in T-SQL, like so:
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
To return orders that were shipped on a date different than (distinct from) the input date @dt, you would use the following query:
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE shippeddate IS DISTINCT FROM @dt;
The workaround that does work in T-SQL uses a combination of the EXISTS predicate and the EXCEPT operator, like so:
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
In Part 1 I also discussed scenarios where you need to join tables and apply distinctness-based semantics in the join predicate. In my examples I used tables called T1 and T2, with NULLable join columns called k1, k2 and k3 in both sides. According to the standard, you would use the following code to handle such a join:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON T1.k1 IS NOT DISTINCT FROM T2.k1
AND T1.k2 IS NOT DISTINCT FROM T2.k2
AND T1.k3 IS NOT DISTINCT FROM T2.k3;
For now, similar to the previous filtering tasks, you can use a combination of the EXISTS predicate and the INTERSECT operator in the join’s ON clause to emulate the distinct predicate in T-SQL, like so:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
When used in a filter, this form is SARGable, and when used in joins, this form can potentially rely on index order.
If you would like to see the DISTINCT predicate added to T-SQL, you can vote for it here.
If after reading this section you still feel a bit uneasy about the DISTINCT predicate, you’re not alone. Perhaps this predicate is much better than any existing workaround we currently have in T-SQL, but it’s a bit verbose, and a bit confusing. It uses a negative form to apply what in our minds is a positive comparison, and vice versa. Well, no one said that all the standard suggestions are perfect. As Charlie noted in one of his comments to Part 1, the following simplified form would work better:
It’s concise and much more intuitive. Instead of X IS NOT DISTINCT FROM Y, you would use:
And instead of X IS DISTINCT FROM Y, you would use:
This proposed operator is actually aligned with the already existing IS NULL and IS NOT NULL operators.
Applied to our query task, to return orders that were shipped on the input date (or that were not shipped if the input is NULL) you would use the following code:
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE shippeddate IS @dt;
To return orders that were shipped on a date that is different than the input date you would use the following code:
SELECT orderid, shippeddate
FROM Sales.Orders
WHERE shippeddate IS NOT @dt;
If Microsoft ever decides to add the distinct predicate, it would be good if they supported both the standard verbose form, and this nonstandard yet more concise and more intuitive form. Curiously, SQL Server’s query processor already supports an internal comparison operator IS, which uses the same semantics as the desired IS operator I described here. You can find details about this operator in Paul White’s article Undocumented Query Plans: Equality Comparisons (lookup “IS instead of EQ”). What’s missing is exposing it externally as part of T-SQL.
NULL treatment clause (IGNORE NULLS | RESPECT NULLS)
When using the offset window functions LAG, LEAD, FIRST_VALUE and LAST_VALUE, sometimes you need to control the NULL treatment behavior. By default, these functions return the result of the requested expression in the requested position, irrespective of whether the result of the expression is an actual value or a NULL. However, sometimes you want to continue moving in the relevant direction, (backward for LAG and LAST_VALUE, forward for LEAD and FIRST_VALUE), and return the first non-NULL value if present, and NULL otherwise. The standard gives you control over this behavior using a NULL treatment clause with the following syntax:
The default in case the NULL treatment clause isn’t specified is the RESPECT NULLS option, meaning return whatever is present in the requested position even if NULL. Unfortunately, this clause is not yet available in T-SQL. I’ll provide examples for the standard syntax using the LAG and FIRST_VALUE functions, as well as workarounds that do work in T-SQL. You can use similar techniques if you need such functionality with LEAD and LAST_VALUE.
As sample data I’ll use a table called T4 which you create and populate using the following code:
DROP TABLE IF EXISTS dbo.T4;
GO
CREATE TABLE dbo.T4
(
id INT NOT NULL CONSTRAINT PK_T4 PRIMARY KEY,
col1 INT NULL
);
INSERT INTO dbo.T4(id, col1) VALUES
( 2, NULL),
( 3, 10),
( 5, -1),
( 7, NULL),
(11, NULL),
(13, -12),
(17, NULL),
(19, NULL),
(23, 1759);
There’s a common task involving returning the last relevant value. A NULL in col1 indicates no change in the value, whereas a non-NULL value indicates a new relevant value. You need to return the last non-NULL col1 value based on id ordering. Using the standard NULL treatment clause, you would handle the task like so:
SELECT id, col1,
COALESCE(col1, LAG(col1) IGNORE NULLS OVER(ORDER BY id)) AS lastval
FROM dbo.T4;
Here’s the expected output from this query:
id col1 lastval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 -1 7 NULL -1 11 NULL -1 13 -12 -12 17 NULL -12 19 NULL -12 23 1759 1759
There is a workaround in T-SQL, but it involves two layers of window functions and a table expression.
In the first step, you use the MAX window function to compute a column called grp holding the maximum id value thus far when col1 is not NULL, like so:
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4;
This code generates the following output:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 5 7 NULL 5 11 NULL 5 13 -12 13 17 NULL 13 19 NULL 13 23 1759 23
As you can see, a unique grp value is created whenever there’s a change in the col1 value.
In the second step you define a CTE based on the query from the first step. Then, in the outer query you return the maximum col1 value thus far, within each partition defined by grp. That’s the last non-NULL col1 value. Here’s the complete solution code:
WITH C AS
(
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
MAX(col1) OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS lastval
FROM C;
Clearly, that’s a lot more code and work compared to just saying IGNORE_NULLS.
Another common need is to return the first relevant value. In our case, suppose that you need to return the first non-NULL col1 value thus far based on id ordering. Using the standard NULL treatment clause, you would handle the task with the FIRST_VALUE function and the IGNORE NULLS option, like so:
SELECT id, col1,
FIRST_VALUE(col1) IGNORE NULLS
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM dbo.T4;
Here’s the expected output from this query:
id col1 firstval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 10 7 NULL 10 11 NULL 10 13 -12 10 17 NULL 10 19 NULL 10 23 1759 10
The workaround in T-SQL uses a similar technique to the one used for the last non-NULL value, only instead of a double-MAX approach, you use the FIRST_VALUE function on top of a MIN function.
In the first step, you use the MIN window function to compute a column called grp holding the minimum id value thus far when col1 is not NULL, like so:
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4;
This code generates the following output:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 3 7 NULL 3 11 NULL 3 13 -12 3 17 NULL 3 19 NULL 3 23 1759 3
If there are any NULLs present prior to the first relevant value you end up with two groups—the first with the NULL as the grp value and the second with the first non-NULL id as the grp value.
In the second step you place the first step’s code in a table expression. Then in the outer query you use the FIRST_VALUE function, partitioned by grp, to collect the first relevant (non-NULL) value if present, and NULL otherwise, like so:
WITH C AS
(
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
FIRST_VALUE(col1)
OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM C;
Again, that’s a lot of code and work compared to simply using the IGNORE_NULLS option.
If you feel that this feature can be useful for you, you can vote for its inclusion in T-SQL here.
ORDER BY NULLS FIRST | NULLS LAST
When you order data, whether for presentation purposes, windowing, TOP/OFFSET-FETCH filtering, or any other purpose, there’s the question of how NULLs should behave in this context? The SQL standard says that NULLs should sort together either before or after non-NULLs, and they leave it to the implementation to determine one way or the other. However, whatever the vendor chooses, it needs to be consistent. In T-SQL, NULLs are ordered first (before non-NULLs) when using ascending order. Consider the following query as an example:
SELECT orderid, shippeddate
FROM Sales.Orders
ORDER BY shippeddate, orderid;
This query generates the following output:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06
The output shows that unshipped orders, which have a NULL shipped date, order before shipped orders, which have an existing applicable shipped date.
But what if you need NULLs to order last when using ascending order? The ISO/IEC SQL standard supports a clause that you apply to an ordering expression controlling whether NULLs order first or last. The syntax of this clause is:
To handle our need, returning the orders sorted by their shipped dates, ascending, but with unshipped orders returned last, and then by their order IDs as a tiebreaker, you would use the following code:
SELECT orderid, shippeddate
FROM Sales.Orders
ORDER BY shippeddate NULLS LAST, orderid;
Unfortunately, this NULLS ordering clause is not available in T-SQL.
A common workaround people use in T-SQL is to precede the ordering expression with a CASE expression that returns a constant with a lower ordering value for non-NULL values than for NULLs, like so (we’ll call this solution Query 1):
SELECT orderid, shippeddate
FROM Sales.Orders
ORDER BY CASE WHEN shippeddate IS NOT NULL THEN 0 ELSE 1 END, shippeddate, orderid;
This query generates the desired output with NULLs showing up last:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 11008 NULL 11019 NULL 11039 NULL ...
There is a covering index defined on the Sales.Orders table, with the shippeddate column as the key. However, similar to the way a manipulated filtering column prevents the SARGability of the filter and the ability to apply a seek an index, a manipulated ordering column prevents the ability to rely on index ordering to support the query’s ORDER BY clause. Therefore, SQL Server generates a plan for Query 1 with an explicit Sort operator, as shown in Figure 1.
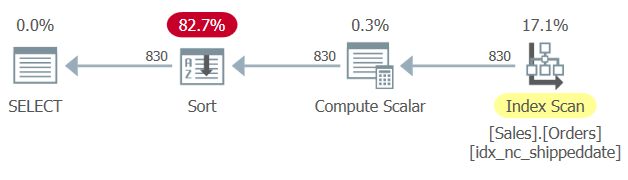 Figure 1: Plan for Query 1
Figure 1: Plan for Query 1
Sometimes the size of the data is not that large for the explicit sorting to be an issue. But sometimes it is. With explicit sorting the query’s scalability becomes extra-linear (you pay more per row the more rows that you have), and the response time (time it takes the first row to be returned) is delayed.
There’s a trick that you can use to avoid explicit sorting in such a case with a solution that gets optimized using an order-preserving Merge Join Concatenation operator. You can find a detailed coverage of this technique employed in different scenarios in SQL Server: Avoiding a Sort with Merge Join Concatenation. The first step in the solution unifies the results of two queries: one query returning the rows where the ordering column is not NULL with a result column (we’ll call it sortcol) based on a constant with some ordering value, say 0, and another query returning the rows with the NULLs, with sortcol set to a constant with a higher ordering value than in the first query, say 1. In the second step you then define a table expression based on the code from the first step, and then in the outer query you order the rows from the table expression first by sortcol, and then by the remaining ordering elements. Here’s the complete solution’s code implementing this technique (we’ll call this solution Query 2):
WITH C AS
(
SELECT orderid, shippeddate, 0 AS sortcol
FROM Sales.Orders
WHERE shippeddate IS NOT NULL
UNION ALL
SELECT orderid, shippeddate, 1 AS sortcol
FROM Sales.Orders
WHERE shippeddate IS NULL
)
SELECT orderid, shippeddate
FROM C
ORDER BY sortcol, shippeddate, orderid;
The plan for this query is shown in Figure 2.
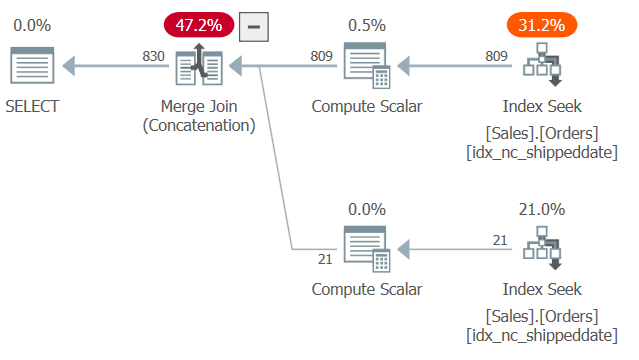 Figure 2: Plan for Query 2
Figure 2: Plan for Query 2
Notice two seeks and ordered range scans in the covering index idx_nc_shippeddate—one pulling the rows where shippeddateis is not NULL and another pulling rows where shippeddate is NULL. Then, similar to the way the Merge Join algorithm works in a join, the Merge Join (Concatenation) algorithm unifies the rows from the two ordered sides in a zipper-like manner, and preserves the ingested order to support the query’s presentation ordering needs. I’m not saying that this technique is always faster than the more typical solution with the CASE expression, which employs explicit sorting. However, the former has linear scaling and the latter has n log n scaling. So the former will tend to do better with large numbers of rows and the latter with small numbers.
Obviously it’s good to have a solution for this common need, but it will be much better if T-SQL added support for the standard NULL ordering clause in the future.
Conclusion
The ISO/IEC SQL standard has quite a lot of NULL handling features that have yet to make it to T-SQL. In this article I covered some of them: the DISTINCT predicate, the NULL treatment clause, and controlling whether NULLs order first or last. I also provided workarounds for these features that are supported in T-SQL, but they are obviously cumbersome. Next month I continue the discussion by covering the standard unique constraint, how it differs from the T-SQL implementation and the workarounds that can be implemented in T-SQL.



{kind=link}
A Semi/Anti-Join with 'IS' can also be done, and is SARGE-able, like so:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
WHERE EXISTS(
SELECT T1.k1, T1.k2, T1.k3
INTERSECT / EXCEPT
SELECT T2.k1, T2.k2, T2.k3
FROM dbo.T2
);