

Trace, diagnose, resolve: Introducing the Infrastructure & Operations app for streamlined troubleshooting
Dynatrace
FEBRUARY 1, 2024
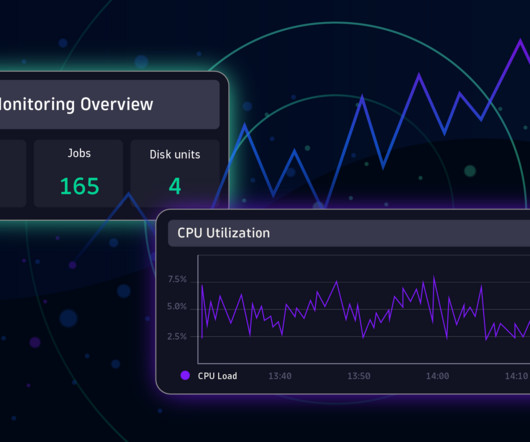
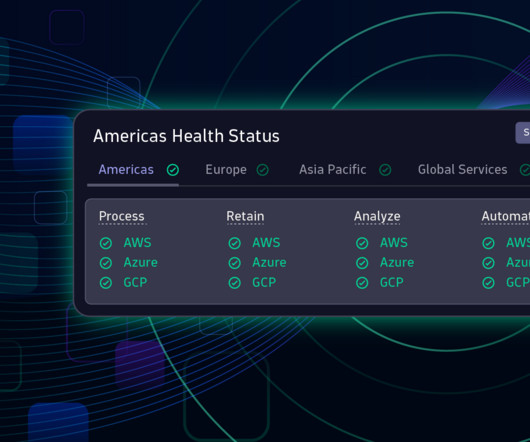
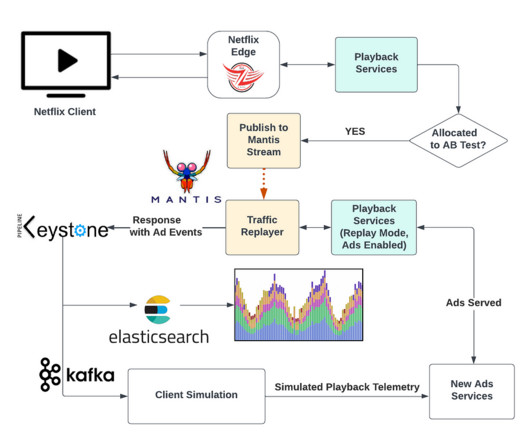
Infrastructure and operations teams must maintain infrastructure health for IT environments. The complex interconnections in cloud-based systems make it crucial to always have a topological overview to understand dependencies. Traditional tools struggle with the intricacy of modern cloud services and containerized applications.













































Let's personalize your content