
Consistent caching mechanism in Titus Gateway
The Netflix TechBlog
NOVEMBER 3, 2022
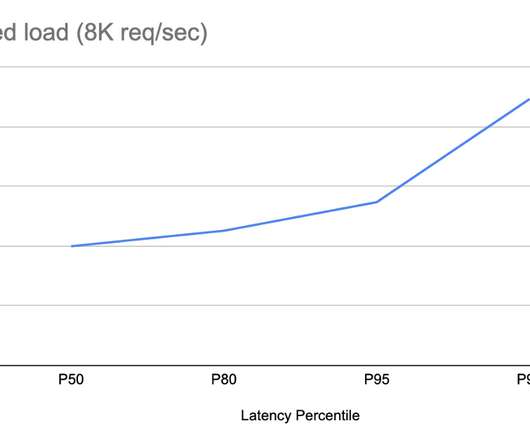
As the number of Titus users increased over the years, the load and pressure on the system increased substantially. We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe.













































Let's personalize your content