


Dynatrace Managed turnkey Premium High Availability for globally distributed data centers (Early Adopter)
Dynatrace
JUNE 25, 2020
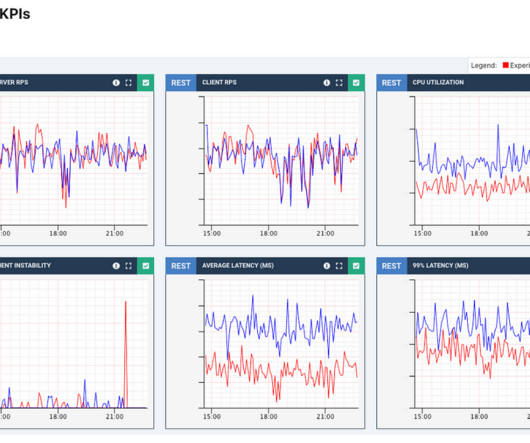
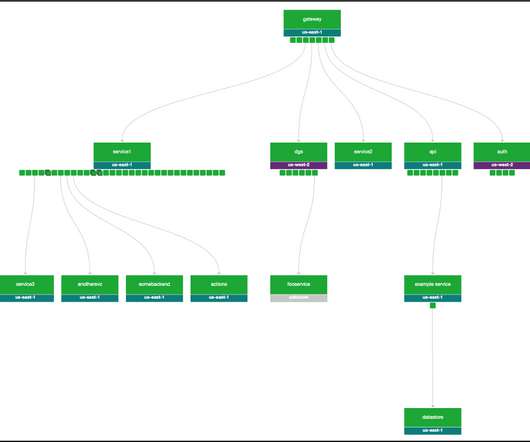
The network latency between cluster nodes should be around 10 ms or less. Near-zero RPO and RTO—monitoring continues seamlessly and without data loss in failover scenarios. Dynatrace Premium HA allows monitoring to continue with near-zero data loss in failover scenarios. With Premium HA, you’re equipped with zero downtime.
























Let's personalize your content