
In this blog series, we explore how organizations can connect Dynatrace to their release processes and leverage Davis® AI to attain full automation, giving Site Reliability Engineering (SRE) teams more time to focus on innovation and other important business goals.
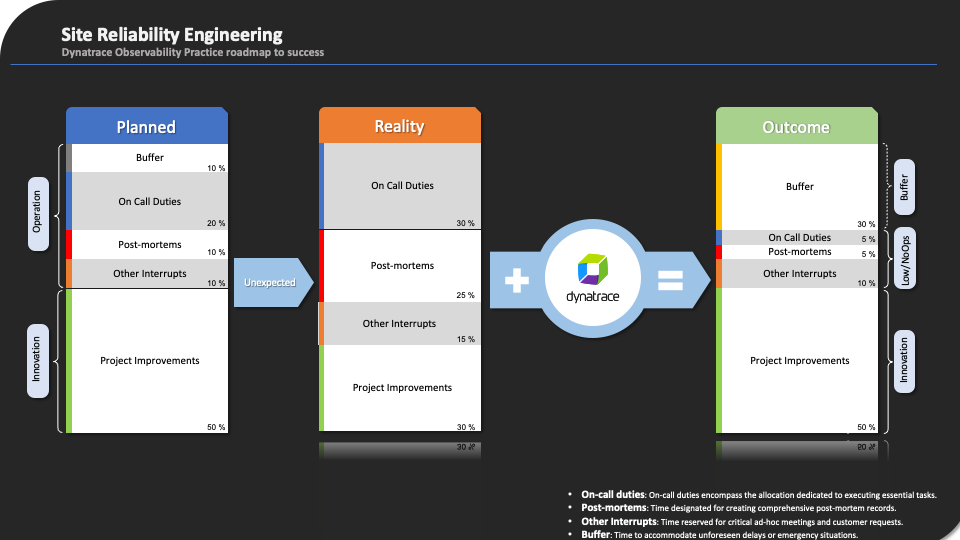
In the realm of SRE, time and effort allocation planning are crucial factors that involve a delicate balance between operational management and project improvements. This intricate allocation strategy can be categorized into two main domains. In this blog post, we’ll delve deeper into these categories to gain a comprehensive understanding of their significance and the challenges they present.
Planned effort
Site Reliability Engineering (SRE) effort and time allocation planning typically fall into two domains:
- Operations Management (50%)
Operations Management includes on-call responsibilities, post-mortem assessments, addressing other interruptions, and buffer time. These tasks collectively ensure uninterrupted production service. - Process Improvements (50%)
The allocation for process improvements is devoted to automation and continuous improvement SREs help to ensure that systems are scalable, reliable, and efficient. This improves the current project and paves the way for future innovation.
Reality
In practice, while both these categories have equal attention, project improvements hold paramount importance for business outcomes. SREs invest significant effort in enhancing software reliability, scalability, and dependability. Regrettably, recent reports indicate that SREs spend a substantial portion of their time addressing build issues and managing production incidents. This challenge escalates with the growing complexity of cloud systems and organizational aspirations for digital transformation, often leaving minimal time for substantial project improvements. Consequently, organizations grapple with various issues that impact software reliability.
Process Improvements
Organizations are strategically integrating observability into the initial stages of their release processes to tackle these challenges. As they embark on this initiative, SREs are tasked with identifying an observability solution that aligns seamlessly with their application teams and seamlessly integrates with their existing toolset.
Outcome
Dynatrace plays a pivotal role in this endeavor by empowering application teams through its seamless integration. The Dynatrace integration leverages native features and events that pass through the pipeline. Events serve as logic operators that can trigger or stop subsequent tasks within the pipeline. Additionally, the Site Reliability Guardian serves as the governing entity, making decisions on whether to proceed or halt a specific build based on observable telemetry data supplied by OneAgent during the CI/CD pipeline process. This proactive strategy significantly enhances the chances of success for SREs, providing them with more time to focus on substantial project improvements (50%) and broaden the buffer zone (30%). This empowers them to spearhead innovations that ensure the business is prepared for future expansions.
Integrate DevSecOps with Dynatrace
Software delivery is structured around CI/CD pipelines, which play a critical role in the SRE process and represent the first step toward effective automation. Automated CI/CD pipelines greatly reduce the occurrence of manual errors. They provide continuous feedback to developers and enable rapid product iterations. Elevating the efficiency of release pipelines is one key to producing high-quality software; it mitigates the need for post-incident analyses and on-call duties for the SRE team. It also returns valuable time back to the SRE team.
A few avenues for elevating CI/CD pipelines are:
- Enhancing the extent of automated test coverage during the testing phase.
- Embracing the tenets of DevOps and DevSecOps methodologies anchored in engineering principles.
- Identifying and automating the validation of business/application Service Level Objectives (SLOs) during release cycles.
- Streamlining the CI/CD process to ensure optimal efficiency.
To realize these goals, SRE teams can seamlessly follow a three-step process within their Dynatrace environment:
- Commencement (optional): If desired, initiate a Dynatrace workflow task to establish a connection with the DevOps tool using HTTP. This step is only necessary if you intend to control the build creation process through Dynatrace.
- Push events: Configure your DevOps tool to dispatch deployment events at the inception of the deployment process. Additionally, introduce annotation events to notify Dynatrace of the progress within your testing phase. These events serve as logical operators that dictate the course of the release process.
- Automated validation and progression: Depending on the configuration of your tasks, Site Reliability Guardian (SRG) validation can be automatically activated to promote or disapprove the advancement of a build towards production.
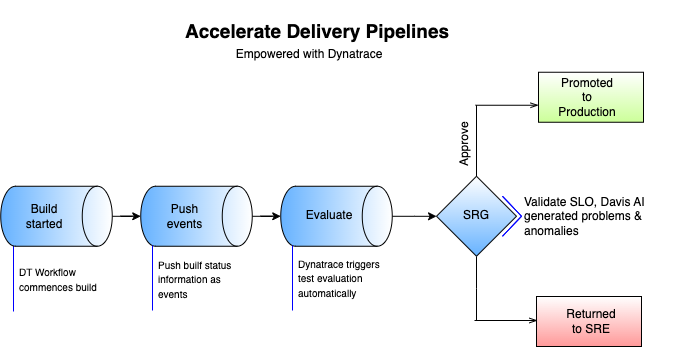
This integration leads to complete automation with end-to-end pipeline visibility, thereby reducing the heavy lifting of release management for SRE teams and empowering them to focus on innovation, which catalyzes organizational growth.
Designing systems for reliability
Engineering teams must extend their focus beyond functional and load tests to instill assurance in the software release process via automated cycles. The rationale is that, during actual production, variables can induce outcomes that are different from those predicted in standardized tests. Thus, more comprehensive testing becomes essential to embrace unpredictability and mirror real-world conditions. These practices are commonly known as “chaos engineering.”
By embracing chaos engineering practices, development teams cultivate a higher degree of confidence in the robustness of their applications within specific production scenarios. However, the very nature of chaos engineering introduces a challenge: identifying the responsible service when a failure occurs. This is where Dynatrace Davis AI comes into play, leveraging telemetry data from your services. Davis AI automatically establishes a baseline of each service’s behavior, learned during the development and functional testing phases, and subsequently identifies the underlying causes of failures, thereby eliminating the uncertainty of the root cause and “war room” scenarios.
To illustrate, a CI/CD pipeline setup has a functional test phase followed by a chaos-engineering test. The chaos engineering test was structured to randomly slow down a Docker container and, thereby, a critical service for the application. During this phase, Davis AI automatically identifies that a key business request has breached its automated baseline due to a significant Mongo database slowdown. Moreover, Davis AI identifies the reason behind the slowdown and pinpoints the exact query that caused the problem.
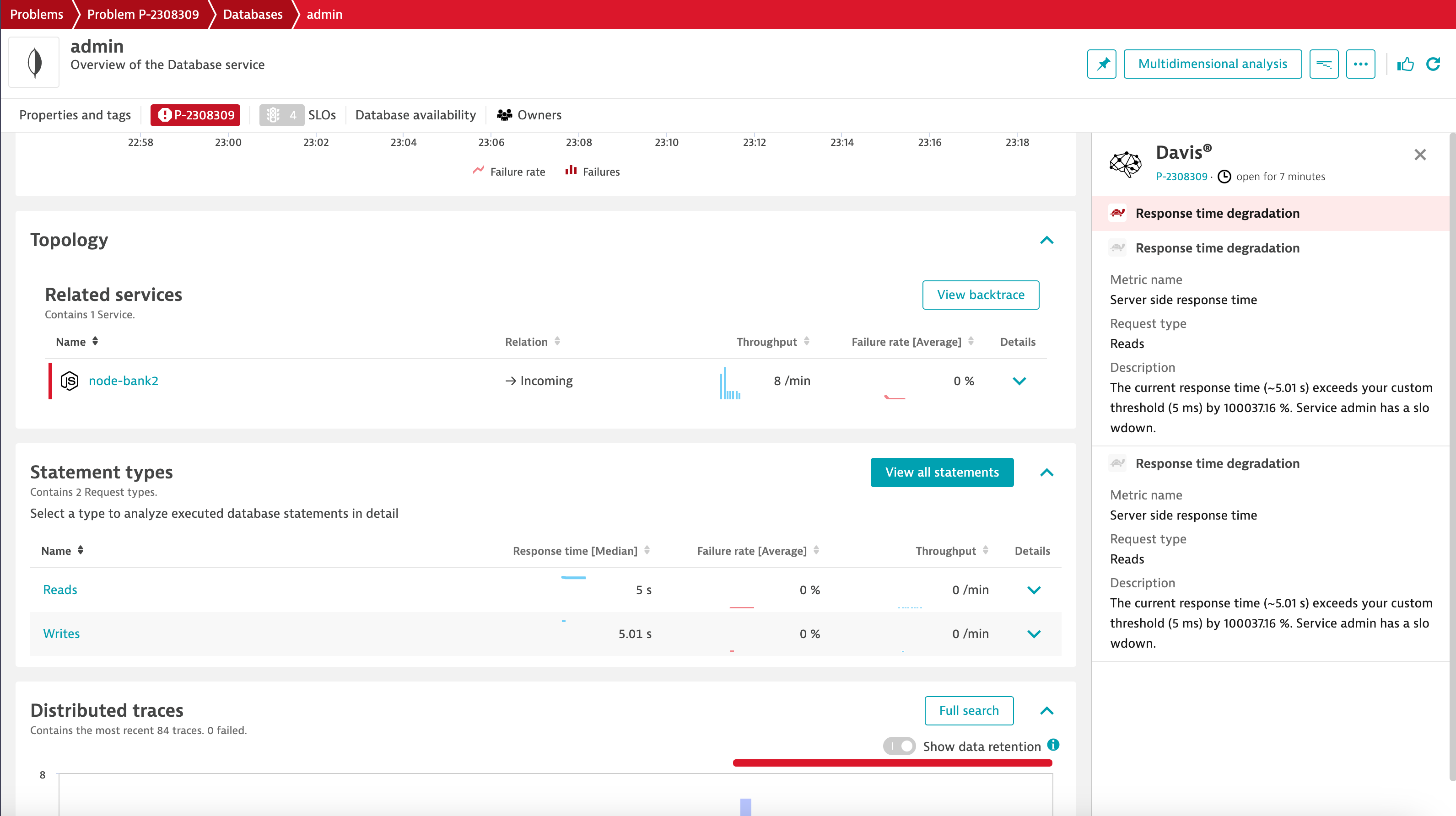
With Davis AI’s contextual capabilities, embracing chaos engineering and making application code robust and better prepared for production deployments is easy.
Reduce operations overhead
Ideally, no bugs are reported once software is deployed to production. However, this is highly unlikely. Therefore, it’s important to have a process in place to minimize downtime in the event of a failure.
Davis AI assists with automated root cause analysis, providing details of the underlying services, traces, logs, and user sessions that caused the failure. This can save SRE teams from the time and effort of debugging or a war room scenario. By identifying the exact code or trace that causes a failure, Davis AI helps teams fix problems quickly and significantly reduces MTTR. In addition, if you configure an automated remediation workflow, Dynatrace invokes it and restores applications with virtually no downtime.
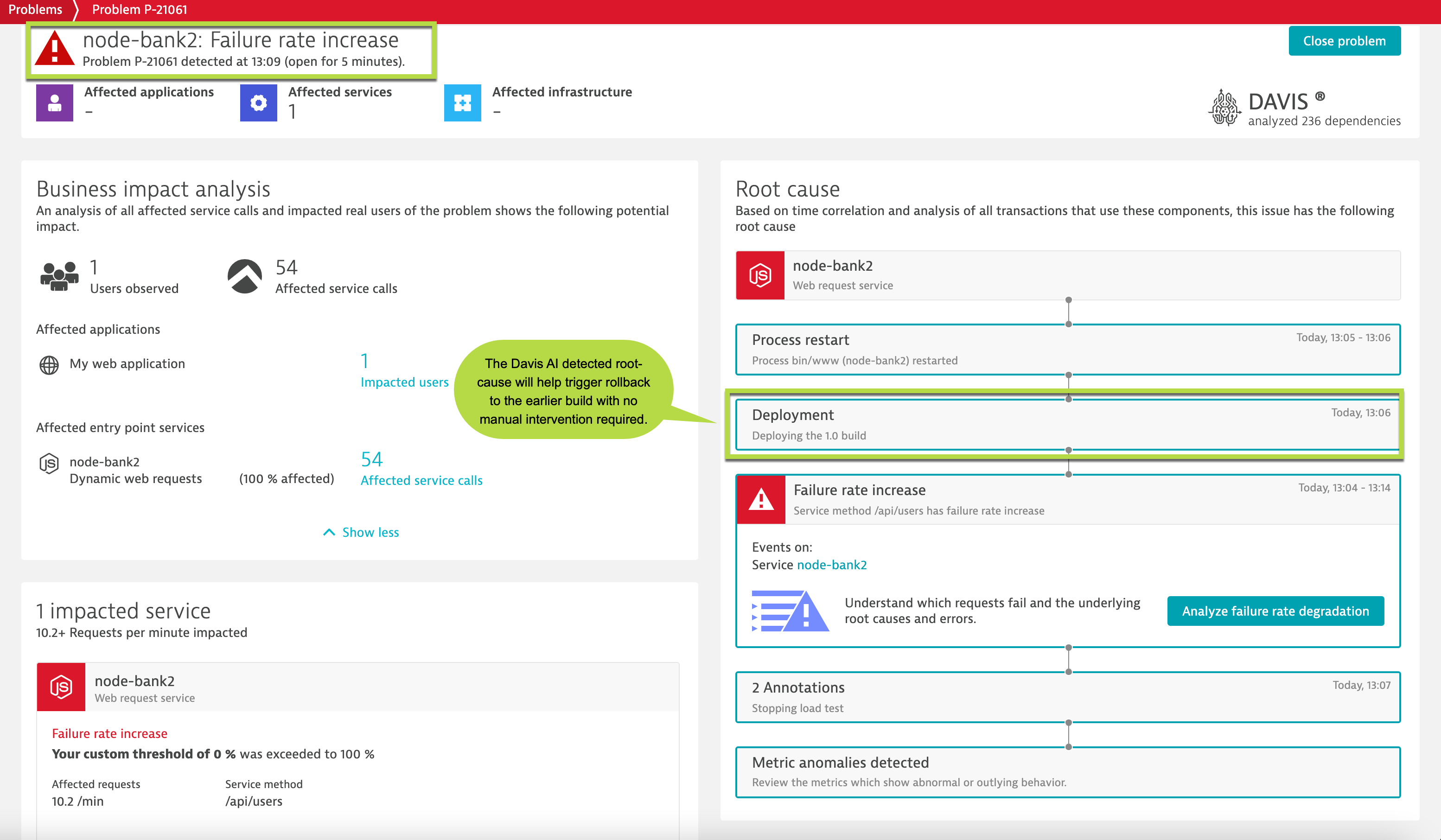
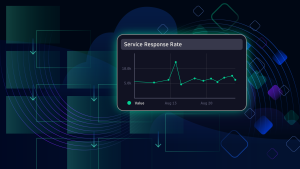
In the above screenshot, one of the requests in the application reports errors. Davis AI identifies that this anomaly was reported in the newer releases. Davis AI captures and relays the details of previous and current builds to the remediation workflow. The remediation workflow uses this information to roll back the build, leaving Davis AI to automatically validate and close detected problems.
Dynatrace Observability empowers the SRE team, propelling them towards LowOps/NoOps. This allows them to prioritize innovation, strategic goals, and minimize downtime while optimizing the delivery of perfect software. In our next blog post in this series, we’ll delve into the step-by-step process of automating the release pipeline using Dynatrace best practices.


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum