
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support…
The Netflix TechBlog
SEPTEMBER 29, 2022
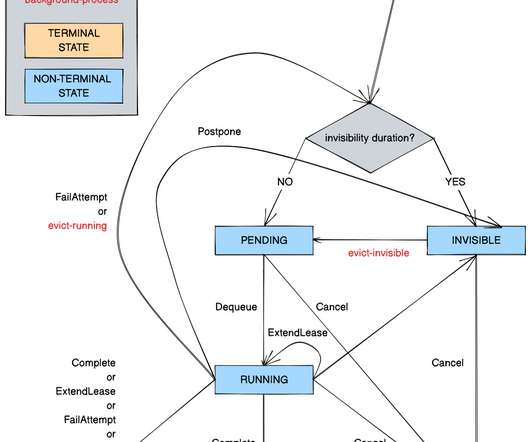
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform.











































Let's personalize your content