

Implementing a Self-Healing Infrastructure With Kubernetes and Prometheus
DZone
MAY 3, 2023
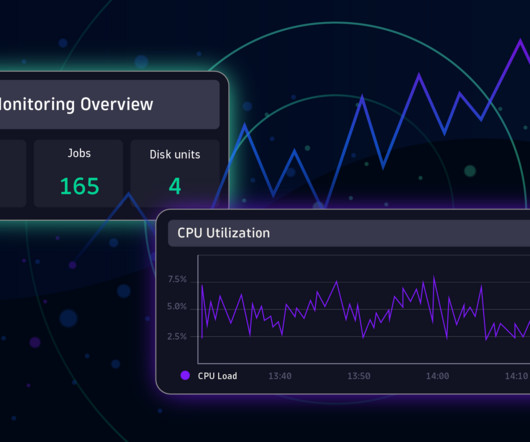
In today's world, the need for highly available and fault-tolerant systems is more important than ever. Furthermore, with the increased adoption of microservices and containerization , the need for a reliable infrastructure that can automatically detect and recover from failures has become critical.













































Let's personalize your content