Optimizing Your Images Didn’t Improve Your Load Time? Here’s Why
MachMetrics
JANUARY 16, 2020
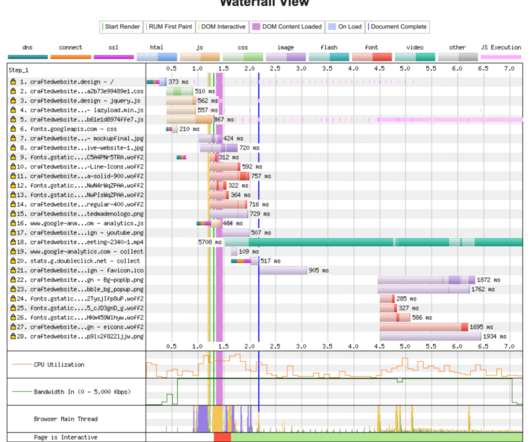
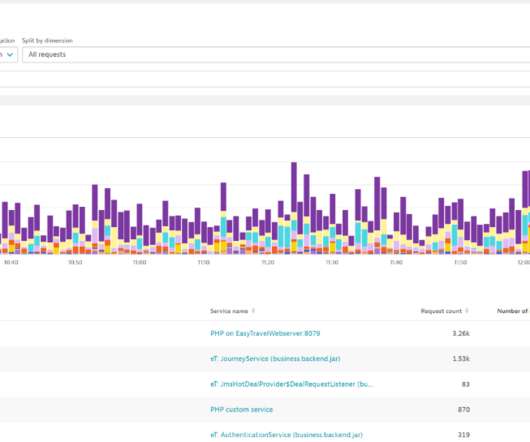
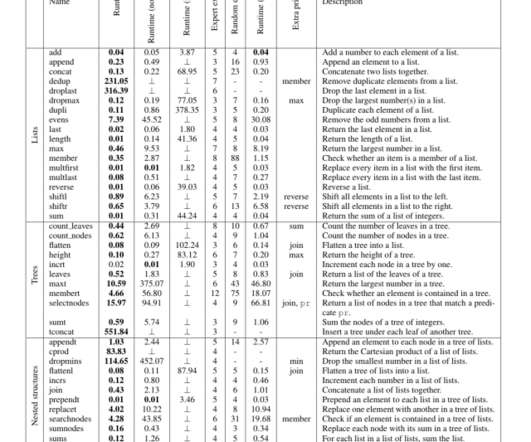
Optimizing your images is often the very first suggestion that any performance writer or consultant will make when it comes to optimizing a website. We’re no exception. Make no mistake, this is a key step to take and should absolutely be a part of your web design/development routine. However, what do you do when you optimize your images and still don’t see a noticeable improvement in the performance of your site?





























Let's personalize your content