
Data Ingestion: Types, Tools, Challenges & Best Practices
Data fuels insight-driven business decisions for enterprises today– be it planning, forecasting market trends, predictive analytics, data science, machine learning, or business intelligence (BI).
But to be fully useful, data must be:
- Extracted from disparate sources in different formats
- Available in a unified environment for access to enterprise
- Abundantly and readily available, and
- Clean
If executed poorly, incomplete or incorrect data extraction can lead to misleading reports, bogus analytics conclusions, and inhibited decision-making.
It is where data ingestion comes in handy as a process that helps enterprises make sense of the ever-increasing volumes and complexity of data. To get the most value out of it, dive deeper into what data ingestion is with this comprehensive guide. It also discusses how to implement data ingestion, tools, best practices, benefits, and more.
What is data ingestion?
To ingest something means to take something in or absorb something.
Data ingestion is the process of moving data (especially unstructured data) from one or more sources into a landing site for further processing and analysis.
It is also the first stage in a data engineering pipeline where data coming from various sources start its journey. Here, the data is prioritized and categorized, making it flow smoothly in the further layers of the pipeline, as shown below. Thus, ingestion brings data into the processing stage or storage layer of the data engineering pipeline.
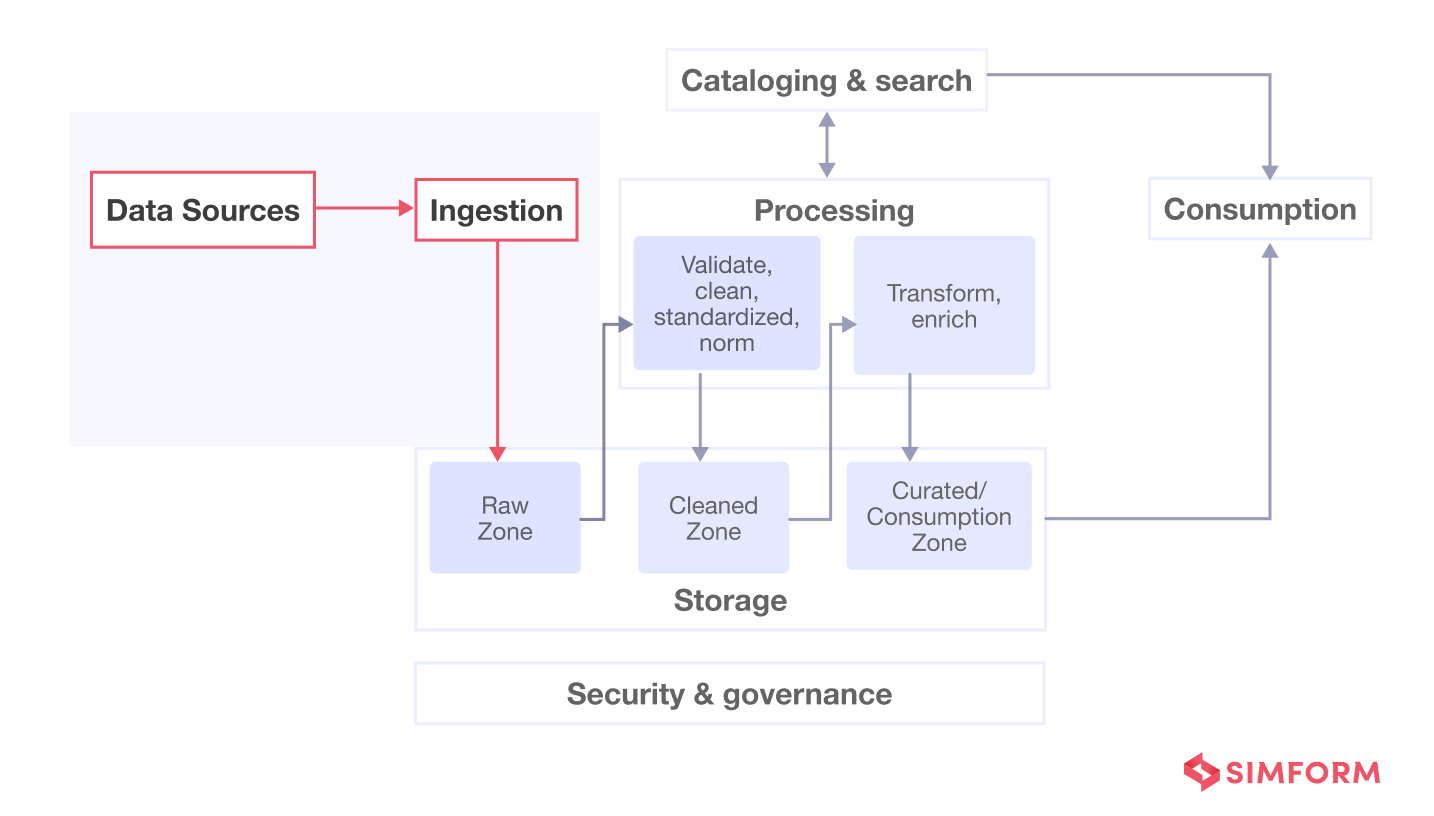
It is a crucial stage as it helps understand the size and complexity of the data, which affects the data architecture and every decision related to it down the road.
Data ingestion can be done in two ways, mainly as discussed below.
Data Ingestion Types
- Batching/batch ingestion
Batching is when data is ingested in discrete chunks at periodic intervals rather than collected immediately as it is generated. The ingestion process waits until the assigned amount of time has elapsed before transmitting the data from original source to storage. The data can be batched or grouped based on any logical ordering, simple schedules, or criteria (such as triggering certain conditions).
This technique is optimized for high ingestion throughput and faster query results. It is typically less expensive and beneficial for repeatable processes or when real-time data is not required. For example, when reports have to be generated on a daily basis.
- Streaming/real-time ingestion
Here, ingestion occurs in real-time, where each data point is imported immediately as the source creates it. The data is made available for processing as soon as it is needed to facilitate real-time analytics and decision-making. Real-time ingestion is also called streaming or stream processing.
This approach is used when data collected is time-sensitive and its velocity will be high. For instance, data coming from oil tanks’ sensors is collected in real-time as it is critical to predict any leakages. Or, in cases of stock market trading, power grid monitoring, etc., where enterprises have to react to new information rapidly.
It is worth noting that some real-time streaming data platforms (such as Apache Spark) also utilize batch processing. But it simply prepares smaller groups or at shorter intervals and does not process data points individually. It is often called micro batching, considered a distinct data ingestion type by some.
Check out how we used micro batching for a market intelligence solution
Both ingestion types have their pros and cons. But what you choose depends on your business requirements. While streaming is best for up-to-the-minute data and insights, batching is more practical and efficient when time isn’t of the essence. You can also build a hybrid data ingestion framework consisting of batch data ingestion and real-time methods.
Pro tip: To design and implement a data ingestion pipeline correctly, It is essential to start with identifying expected business outcomes against your data pipeline. It helps answer questions such as
- How many and what data sources do your business currently have?
- Which sources are relevant to achieving your business outcomes, and which to prioritize?
- Where does your data reside? (Cloud/on-premise)
- What data needs to be extracted beforehand?
- Does quick data availability affect the business outcome?
- How often should the data be accessed?
Information gathered from such questions will help choose ingestion techniques (batch/real-time/hybrid) as well as choose the best tools suited to achieve the expected results.
Call it the “blueprinting” stage, where you map out the ideal architecture of the data ingestion layers with the right tools. More on data ingestion tools in the section below!
Data Ingestion Tools

The right data ingestion tools are the backbone of a robust ingestion process, and here are some popular tools you can consider.
- Amazon Kinesis
It helps you ingest real-time data from various sources and process and analyze data as it arrives. In addition, it offers different capabilities such as Kinesis Data Streams, Kinesis Data Firehose, and and more for streaming data ingestion at any scale cost-effectively with tools that best suit your requirements.
- Apache Kafka
It is an open-source distributed event streaming platform. Event streaming captures real-time data from event sources like mobile devices, sensors, databases, cloud services, and software applications. Kafka durably stores the data for later retrieval for processing and analysis. Its other core capabilities include high throughput, scalability, and high availability.
- Apache Flume
It is a tool designed to efficiently collect, aggregate, and move large amounts of log data. It has a flexible and simple architecture (based on streaming data flows) that loads data from various resources into HDFS (a Hadoop Distributed File System). It is also robust and fault-tolerant with many failover, reliability, and recovery mechanisms.
- Airbyte
It is also an open-source data ingestion tool focusing on extracting and loading data. It eases the setting up of pipelines and maintains secure flow throughout the pipeline. It can provide access to both raw and normalized data and integrates 120+ data connectors.
The tools mentioned above barely scratch the surface. There are various tools available out there, including Apache Gobblin, Google BigQuery, Amazon Redshift, Microsoft Azure Data Factory, analytics databases like Amazon Athena, etc. Here are some tips to choose the right ones.
Tips for choosing the right data ingestion tools
- Consider how quickly you will need access to the data for analysis.
- Take into account these key parameters – data velocity, size, frequency (batch or real-time), and format (structured format, semi-structured, or unstructured)
- Consider the experience/capabilities of your data teams and the specific tooling required.
- Consider how many data connectors the tool will support (Shopify, Facebook, NetSuite, etc.)
- Also, take account of these factors – reliability and fault tolerance, latency, auditing and logging, normalization, budget, community support for the tool, and checking data quality.
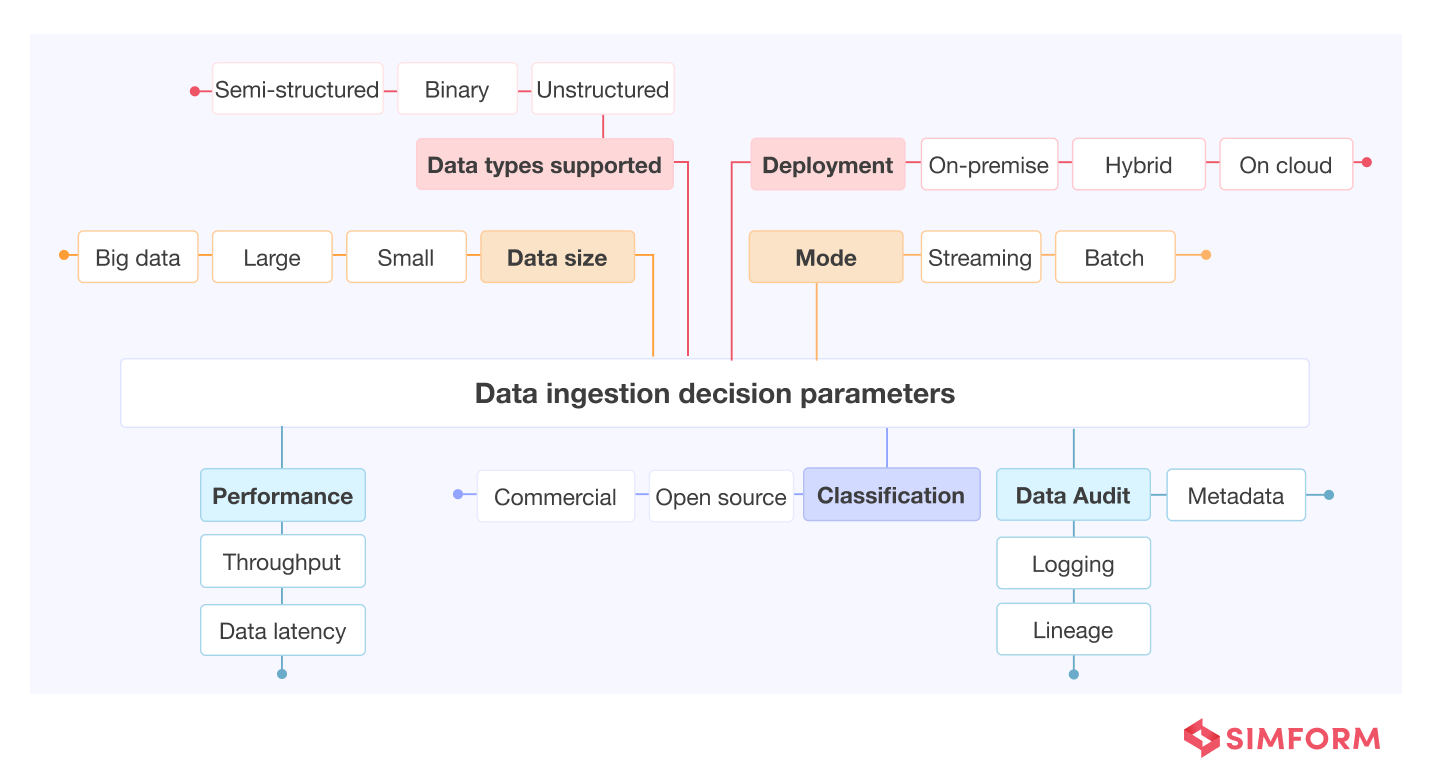
There is no silver bullet to picking a data ingestion tool. You may want to choose one depending on your business requirements and the type of ingestion. For instance, Amazon Kinesis Video Streams can be a great option for securely capturing, processing, and storing video streams.
Benefits of data ingestion
Data ingestion offers various benefits, enabling teams to manage data more efficiently and gain business advantage from it. Some of these benefits include:
- Makes data readily available
Efficient ingestion process collects data from various sources and makes it available at the right destination applications for analytics to authorized users, including BI analysts, sales, developers, and others who need to access it. Additionally, it also increases data availability for applications that require real-time data.
- Makes data simple, uniform, and less complex
Advanced ingestion processes combine extract, transform and load (ETL) tools and solutions too, which transform variable formats of data into predefined formats before delivering to a landing area. Thus, it makes the data uniform and readable for analysis and manipulation. It also makes data less complex and easier for different stakeholders to use (especially ones from non-technical backgrounds).
- Improves business intelligence and real-time decision-making
Once data is ingested from various data source systems, businesses can easily draw valuable BI insights with analytical tools. Moreover, real-time ingestion facilitates the availability of constantly updated information, allowing businesses to make even more accurate by-the-minute predictions.
Businesses can also improve applications and provide a superior user experience with insights extracted from the ingested data.
- Saves time and money
A data ingestion layer that uses tools to automate the process also saves time for data engineers that previously carried out tasks manually. It enables them to dedicate their time and resources to more pressing tasks or focus on deriving more business value from the data.
Now that we know the what and why of data ingestion, let’s distinguish between data ingestion and ETL, which are different but closely related concepts often used interchangeably.
Data ingestion vs. ETL
Data ingestion and ETL are similar processes but with different goals.
Data ingestion is a broader term referring to transporting data from a source location to a new destination for further processing or storage, such as in a data lake or data warehouse.
But oftentimes, the moving data include multiple data formats from different sources. It is where ETL helps.
ETL is a specific three-step process that extracts, transforms, and then loads data to create a uniform format. It is a more specific process with the goal of delivering data in a format that matches the requirements of the target destination.
Want to know how we built a scalable ETL architecture for a client catering to school districts that resulted in 10X faster data processing?
Check out the case study on big data and analytics solution for school districts
Data ingestion vs. data integration
Another concept that is often confused with data ingestion is data integration. Both describe moving data from one system to another, so what is the difference?
Data ingestion mainly refers to the process of collecting, acquiring, and importing data from various sources into a storage or processing system for further analysis, processing, or storage. It is often the first step of a data engineering pipeline, but it can also be an ongoing process as new data becomes available.
Data integration, on the other hand, is a broader concept that encompasses the process of combining data from different sources, often with different structures, formats, or semantics, into a cohesive and unified data view. It pulls data out of a database and puts it back into another system, such as a data warehouse or a data lake.
However, the data integration process may involve real-time data ingestion, data transformation, data enrichment, data replication, and data consolidation. It aims to create a single, consolidated, easier view of data that can be used for analysis, reporting, or storage in a data warehouse or a data lake.
To better understand the concept of data ingestion, we have discussed how it works below.
How Data Ingestion works?
The key elements of the data ingestion stage include data sources, data destinations, and the process of moving the data from multiple sources to one or multiple destinations.
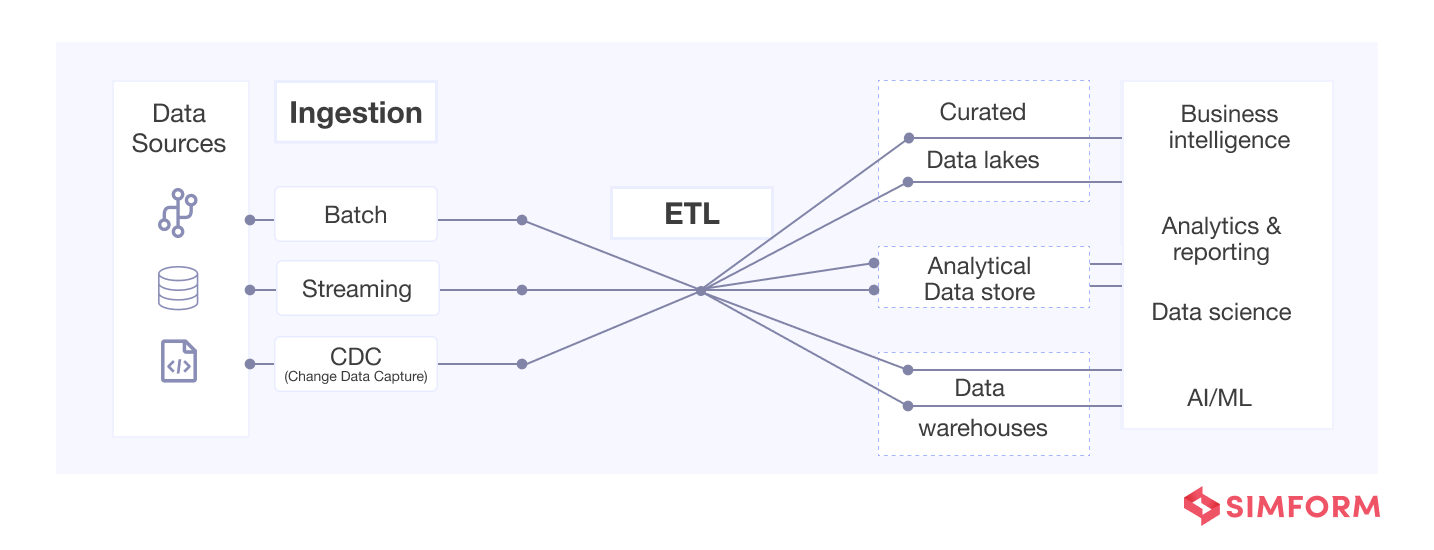
Data Sources
The ingestion stage starts with collecting data from assorted sources. Today’s organizations source data from websites, IoT devices, customers, SaaS apps, internal data centers, and social media, other human interactions on the internet, and many other external sources.
The first step for implementing an effective data ingestion process is prioritizing the multiple data sources. It helps prioritize business-critical data during ingestion. This may require meetings with product managers and other stakeholders to understand core business data.
Moreover, numerous (maybe hundreds) big data sources exist in diverse formats coming at different speeds. Thus, it is challenging to ingest data at a reasonable pace and process it efficiently. But the right tools can help automate the process. Then, individual files/data items are validated and routed to the correct destinations.
Data Destinations
Data destinations are where data is loaded and stored for access, use, and analysis by an organization. Data may end up in different target sites such as cloud data warehouses, data lakes, data marts, enterprise resource planning (ERP) systems, document store, customer relationship management (CRM), and a range of other systems.
Data lakes are storage repositories that hold large amounts of raw data in their native format. Here, the data structure and requirements are not defined until data is to be used. Whereas data warehouses store data in highly structured repositories.
Ingestion pipeline
A simple ingestion pipeline consumes data from one or more points of origin. It then cleans or filters it up a bit for enrichment before writing it into a destination or a set of destinations. More complex ingestion may facilitate more complex transformations, such as converting the data into easily readable formats for specific analytics.
Data ingestion is a time-consuming, complex process requiring multiple steps especially for enterprises that need to implement a large-scale data engineering pipeline correctly. Check out this ebook on how to build enterprise data pipelines with examples from prominent organizations worldwide.
As for the process of ingesting, it can be done in two ways, mainly as discussed below.
Challenges of data ingestion
Implementing and maintaining data ingestion pipelines can be complex and may involve several challenges, such as
- Sluggish or slow process
When data is extracted from different sources, it has a different format, syntax, and attached metadata. It makes the data heterogeneous as a whole and has to be transformed into common formats like JSON files or ones that can be understood by the analytics teams.
The conversion can be a tedious process, taking a lot of time and computing resources. Moreover, it is challenging to authenticate and verify the data at several stages to meet an organization’s security standards.
- Increasing data complexity
With constant evolution, data sources and internet devices have also increased. And businesses find it challenging to keep up with the ever-growing data sources, types, size as well as complexity. It can hamper the chances of building a future-proof data ingestion framework.
- The risk of data security
There is always a risk of security when transferring sensitive data from one point to another. It makes it challenging to meet compliance standards during ingestion. Plus, data teams have to fend off any threats or cyber attacks launched by malicious parties.
Moreover, unreliable connectivity can also disrupt the transfer, causing loss of data and compromising its reliability.
- Ensuring scalability
When ingesting data on a large scale, it can be laborious to ensure data quality and whether it conforms to the format and structure the target destination requires. Thus, large-scale data ingestion can suffer from performance challenges.
- The cost factor
Data ingestion can quickly become expensive due to several factors. For example, there are costs associated with patented tools and specialists to support the ingestion framework, which can be costly to sustain in the long run. Plus, businesses may need to expand storage capacity, servers, and infrastructure to support scale as data volumes grow.
Growing costs associated with large data volumes, backup, slow data processing speeds, and big data security are some biggest challenges organizations face today. Check out this blog on solving modern data challenges with AWS if you meet these challenges.
- Complex legal requirements
Compliance and legal requirements add complexity to the data ingestion process. Data teams have to familiarize themselves with numerous data privacy and protection regulations to ensure they are operating within legal boundaries. For example, complying with HIPAA (Health Insurance Portability and Accountability Act), SOC 2 (Service Organization Control 2), GDPR (General Data Protection Regulation), etc.
Data ingestion best practices
Your analysis that follows ingestion will only be as good as the quality of the data ingested. While there are many challenges associated with carrying out data ingestion successfully, here are some best practices that will help you implement it smoothly.
- Automate as much as possible
As the data volume and complexity grow, it is essential to automate some processes to save time, reduce manual efforts, and increase productivity. Automation can also help achieve architectural consistency, better data management processes, and safety, eventually reducing the data processing time.
Let’s say you want to extract data from a delimited file stored in a folder, cleanse it, and transfer it to the SQL Server. But the process will be repeated every time a new file is dropped in the folder. If you find a tool that can automate this process, it can optimize the entire ingestion cycle.
- Anticipate difficulties and plan accordingly
With the increasing, enormous volumes of data, ingestion becomes more complicated. Thus, outlining challenges associated with specific use case difficulties and planning for them while making a data strategy becomes crucial.
- Enable self-service data ingestion
If your company works on a centralized level, it can be troubling to execute every request if new data sources are added on a regular basis. Opting for automated or self-service ingestion can help business users handle such processes with menial intervention from IT team.
- Document data ingestion pipeline sources
Documentation is a common best practice that also goes for data ingestion. For example, keep a note of what tools you are using with which connectors are set up within the tools. Note any changes or special requirements made for the connector to work. It will help you keep track of where the raw data is coming from and if it can be your lifeline when something goes wrong.
- Create alerting at data source
Creating data alerts, testing, and debugging at the source is much easier than poking around in the downstream data models (analysis/visualization) while fixing issues. For instance, you can use simple tests to ensure your data looks as expected and use tools (like Slack) to set up alerts.
- Keep a copy of all raw data in your warehouse at all times
Storing your raw data in a separate database in your warehouse at all times is critical for protecting the raw data. It acts as a backup if something goes wrong in data processing and modelling. Moreover, having strict read-only access and no transformation tool or write access will strengthen the reliability of the raw data.
How Simform can help ace data ingestion
A robust data ingestion layer is crucial for efficient downstream reporting and advanced analytics that rely on accessible and consistent data. Furthermore, automated data ingestion can become a vital differentiator in today’s increasingly competitive marketplaces.
Simform’s expert data engineering services can effectively help you bridge the gap between data sources and your business goals. Whether you are planning to build a full-fledged data pipeline or looking for consultation on building a solid data strategy, our solution architects can guide you thoroughly!


