
Amazon DynamoDB Best Practices: 10 Tips to Maximize Performance
Disney+ uses Amazon DynamoDB for its many benefits, such as scalability, low operational and administrative overhead, and high performance. But while DynamoDB can deliver single-digit millisecond performance at any scale, it needs to be modeled carefully with DynamoDB best practices to achieve that performance.
For instance, when it launched in November 2019, Disney+ leveraged pre-partitioning and DynamoDB’s ability to switch between on-demand and provisioned modes to avoid throttling. It used DynamoDB for caching, watchlists, recommendations, and bookmarking.
However, Disney+ was uncertain about the traffic estimates and had expected a large influx of bookmark data into an empty table during the launch. But DynamoDB partitions data as the throughput and data storage grows to maintain a high level of throughput. So the company pre-partitioned its tables to meet the demands of the scale. Additionally, it set a high provisioned throughput write value for these tables before launch. And it switched back to on-demand mode to scale higher if needed. As a result, Disney+ avoided throttles with the combination of these two practices.
In this article, you’ll discover key design best practices to help you efficiently use Amazon DynamoDB and increase its performance. It also discusses when not to use DynamoDB and its common use cases. First, let’s have a quick recap of what Amazon DynamoDB is.
Amazon DynamoDB: An overview
As a business, you wouldn’t want to invest more time and money into how your database infrastructure works at the backend when you can focus on innovation. But DynamoDB provides all at just a click of a button– a functionality businesses and startups want for mission-critical applications and serverless computing.
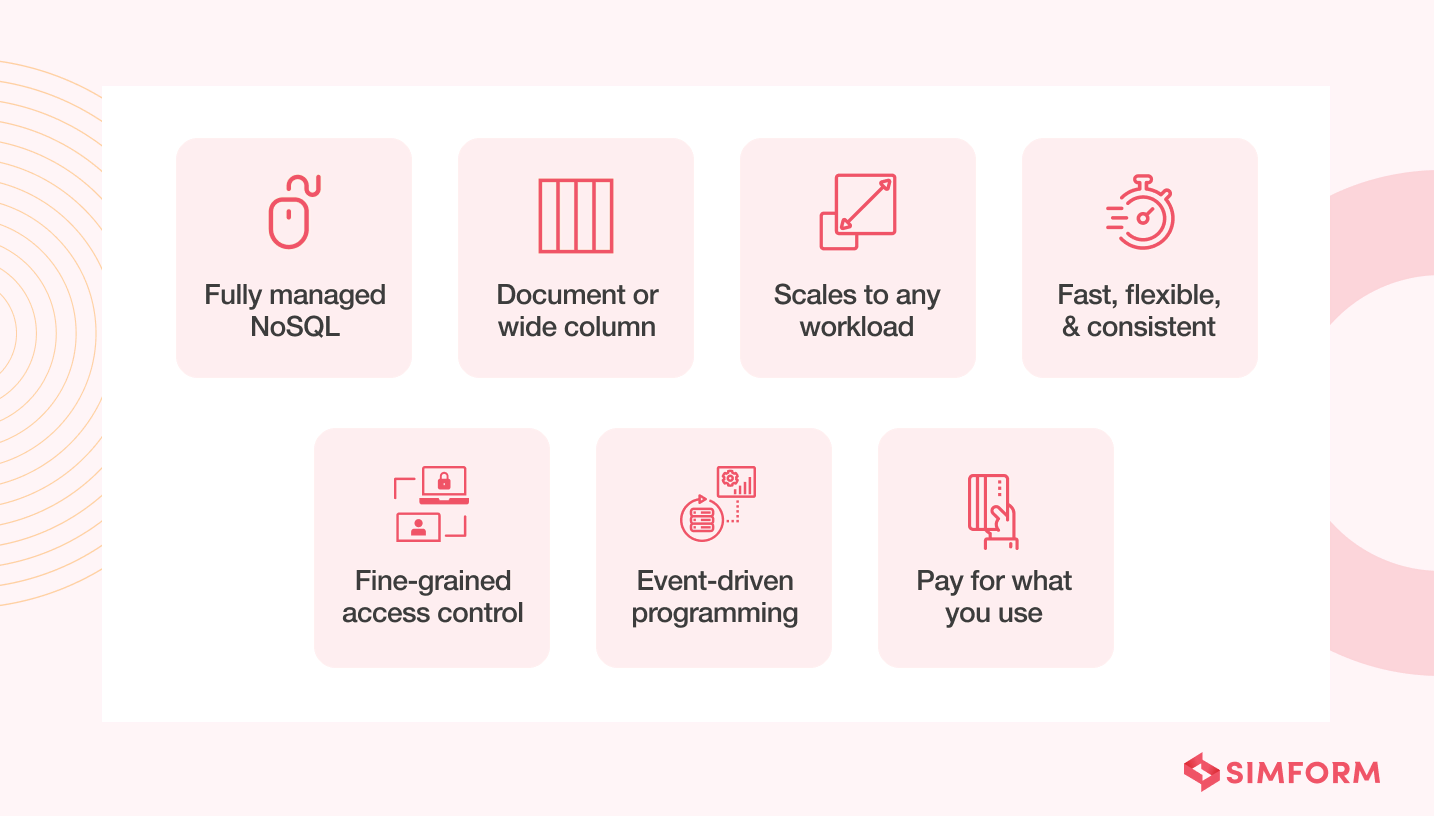
Amazon DynamoDB is a fully managed NoSQL database service from AWS. It is designed to automatically scale tables to adjust for capacity and maintain high performance with zero administration.
- No more provisioning, patching, or managing servers for scalability and availability
- No more installing, operating, or maintaining database software
- Built-in fault tolerance, security, backup and restore, automated multi-Region replication, and more.
AWS does most of the heavy lifting to support DynamoDB. However, you need to be mindful when modeling data in DynamoDB. Below are some recommendations and tips to maximize performance and minimize throughput costs when working with DynamoDB.
10 DynamoDB Best practices
1. Identify your application’s access patterns
First off, working with DynamoDB requires a mindset shift to NoSQL design. You design the schema specifically to make the most important and common queries as fast and inexpensive as possible. And your data structures are tailored to the specific requirements of your business use cases.
So, the first step is to identify the query and access patterns your database system will satisfy. You mustn’t start designing your DynamoDB application until you know what questions it will answer. Therefore, it is crucial to understand the below fundamental properties of your access patterns before you begin:
- Data size
The amount of data that will be stored and requested at a time. It helps determine the most effective way of partitioning data.
- Data shape
NoSQL databases organize data in a way that its shape corresponds with what will be required. It plays a crucial role in increasing speed and scalability.
- Data velocity
Determining the peak query loads to help DynamoDB partition data to best use the I/O capacity. Because to scale, DynamoDB increases the number of partitions available to process queries and distributes data efficiently across them.
After identifying the access patterns, you can make time to model your DynamoDB tables and how data will be organized.
This step will require thoughtful work and effort upfront. For instance, engaging the PMs and business analysts to fully understand your application. But in the long run, you won’t have to worry about scaling your database as your application grows.
Read more on how to solve the bottlenecks of scaling databases
2. Understand the single-table design
Before moving into implementation and coding, it is essential to understand the single-table design pattern of the NoSQL world.
In a traditional relational model database, you create a normalized data model. And extend it later to serve new questions or query requirements when they arise. Here, each data type is organized into its own table.
By contrast, denormalizing data is key to NoSQL design. Here, you jam all your entities into a single table. But ensure that you jam in an efficiently organized way, so the tables are built to handle the access patterns you identified above. No columns and attributes are required, but primary keys uniquely identify every single item. Surely, your tables will look like machine code rather than a simple spreadsheet. But your database will scale to massive levels without performance degradation.
Evaluating and choosing the right database for your business is also recommended. It helps avoid database scalability issues in the future.
3. Table-level best practices
Below are some DynamoDB best practices that can help maximize table read/write efficiency.
- Avoid hot keys
DynamoDB partitions your data by splitting it across multiple instances to scale. And it uses partition keys which are part of the primary keys. Partition keys indicate which instance should store which particular piece of data.
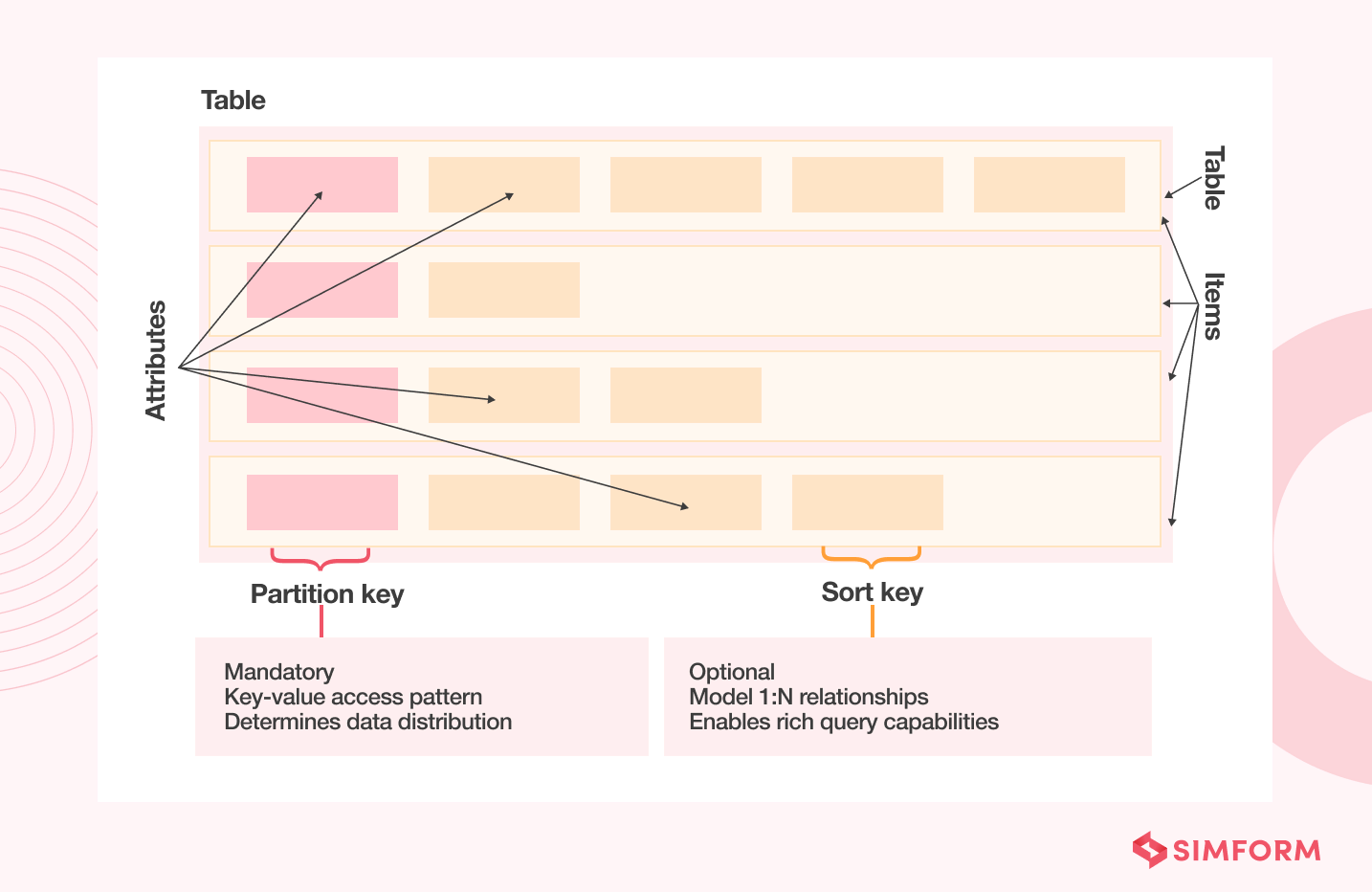
A hot key is a partition key that significantly receives more traffic than other keys in your DynamoDB table. It happens when your data is not modeled correctly or is skewed. And when one part of your table receives a high volume of queries, it can exceed the I/O capacity and cause throttling. Here are some tips to keep in mind:
- Design data keys to distribute traffic uniformly across partitions
- Choose partition keys wisely
- Ensure uniform distribution of reads/writes across partitions to avoid hot partitions
- Store hot and cold data in different tables
For instance, you can consider separating time series data into different tables. If the data for the last two years is accessed more frequently, store it separately from data older than two years. You can provision different capacities for the tables based on their read/write frequencies. It will ensure efficient use of provisioned capacity and minimize throttling.
- Store related data together
“Locality of reference” plays a vital role in speeding response times. Thus, keeping related items as together as possible in your NoSQL system can improve performance and cost-efficiency compared to distributing related data items across multiple tables.
4. Query and scan best practices
- Avoid full-table scans
DynamoDB uses Query and Scan to fetch a collection of data. A Scan operation scans the entire table item by item to retrieve data. A Query operation only scans and retrieves the item belonging to the specified partition key. Thus, Query operations are much faster and also help avoid extra costs.
- Use ‘Parallel Scan’ for big datasets
A Parallel Scan divides your table into segments and then processes each segment simultaneously for faster processing. However, this feature can quickly drain the provisioned capacity and cause throttling if not chosen for the right use cases.
5. Item-level best practices
- Compress large attributes
DynamoDB limits the size of each item you can store in a table. If you need to store more data than the limit permits, you can compress the data using common algorithms such as GZIP. It lets you store more data and reduce storage costs.
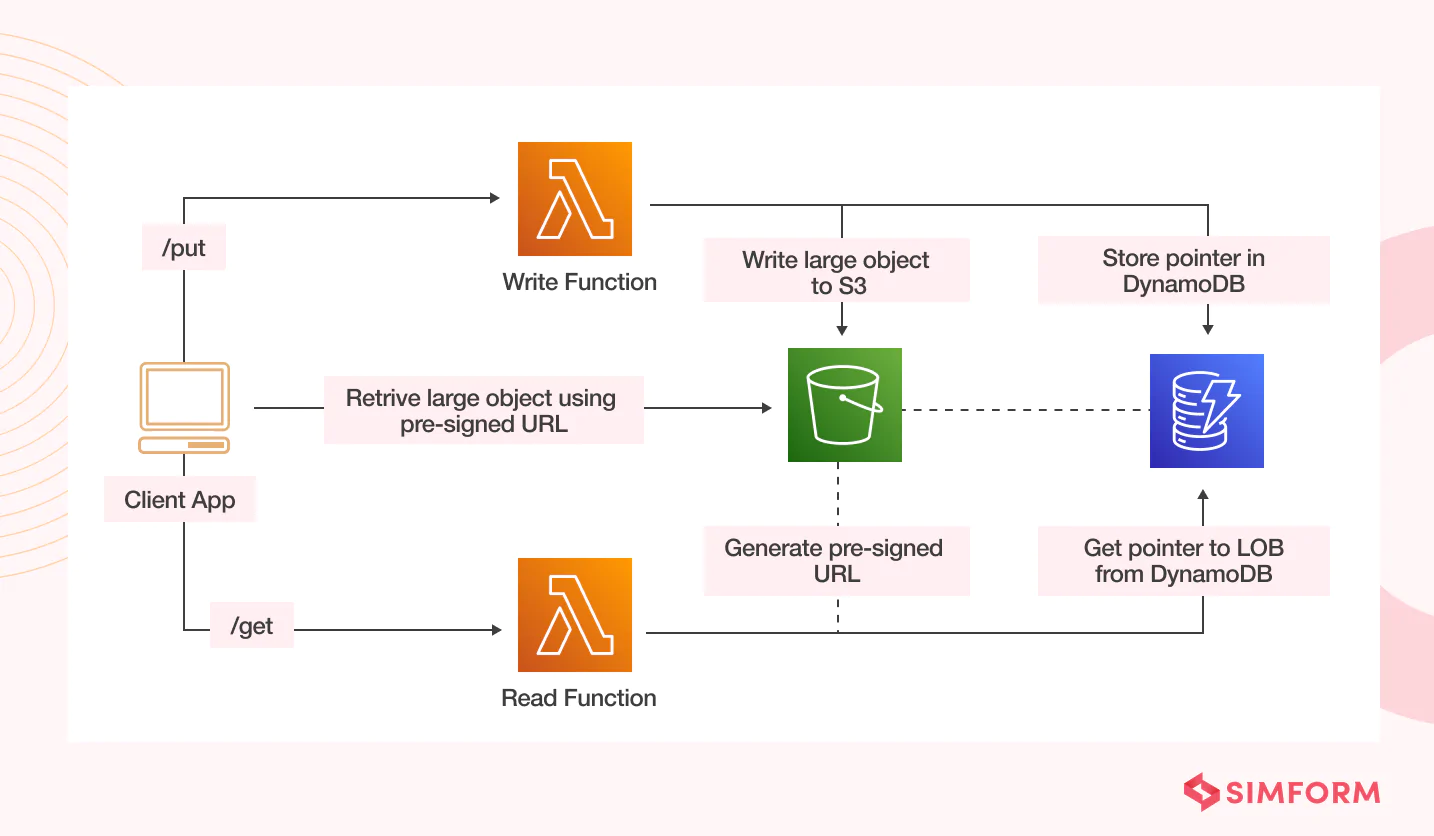
- Store large attributes in Amazon S3
You can also store large items attribute values that do not fit an item limit as objects in Amazon S3. You can then store the S3 object identifier in the DynamoDB item.
- Use shorter attribute names to reduce item size
If you have a lot of items with long attribute names, it can take up a lot of space. Thus, the names should be short, intuitive, and easy to understand. For instance, use DOB instead of Date of Birth.
6. Use secondary indexes efficiently
At times, you may have multiple and conflicting access patterns for a particular item in your DynamoDB table. Here, secondary indexes allow you to handle the additional access patterns by copying all your data from the main table to a secondary index in a redesigned shape.
However, their inefficient use or overuse can unnecessarily add to costs and reduce performance. So here are some tips you can keep in mind:
- Keep the sizes of indexes as small as possible by choosing projections carefully
- Keep the number of indexes to a minimum
- Optimize frequent queries to avoid table fetches
- When creating local secondary indexes (LSIs), keep in mind the item collection size limits
Use LSIs to avoid additional costs but need strongly consistent index reads. And use global secondary indexes when you need finer control over throughput and your application needs different partition keys than the table.
7. Use on-demand mode to identify traffic patterns
DynamoDB has two capacity modes with specific billing– provisioned and on-demand. In provisioned capacity mode, you specify the amount of read capacity units and write capacity you want available for your tables in advance. If your tables exceed the limit, the requests are throttled.
In on-demand mode, you pay for every single request received to your DynamoDB tables. It means no capacity planning and throttling. For more information, you can refer to Amazon DynamoDB pricing page.
For optimized costs and performance, you can start with on-demand pricing to identify traffic patterns. If you are unsure of the traffic, the on-demand capacity mode will scale your tables with the ideal amount of read and write requests. Once you discover the traffic patterns, switch to provisioned mode to save costs with Auto scaling.
Want to know more about AWS Auto Scaling?
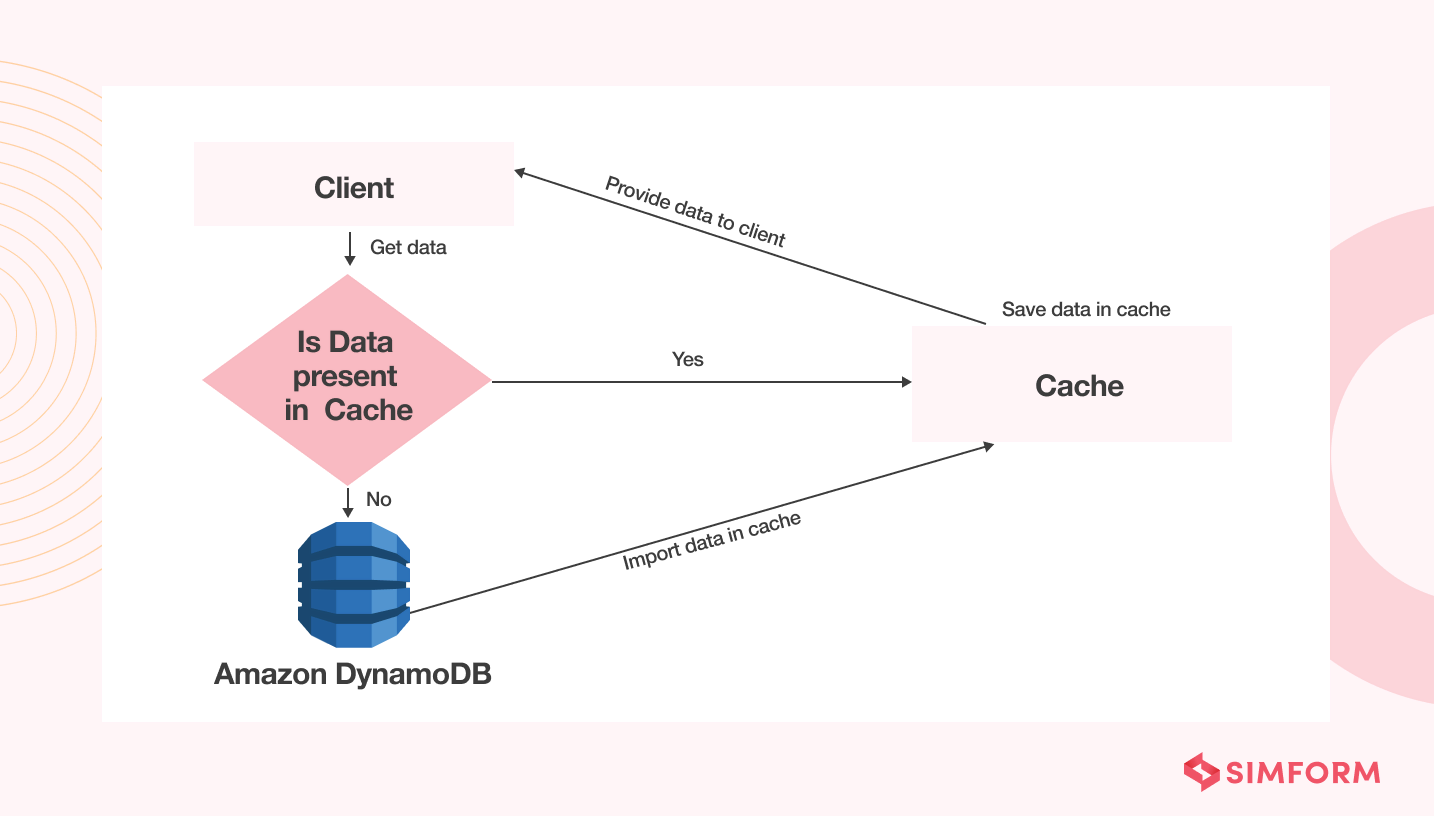
8. Use caching for read-heavy workloads
It is a good DynamoDB best practice to use caching for read-heavy or frequently accessed items. It can reduce your DynamoDB costs by 80% by reducing the number of calls made to your table. Hence, it improves performance and cost-effectiveness.
9. Use IAM policies for security and enforce best practices
You can use IAM policies to control who is allowed access to the DynamoDB tables. It also helps implement security best practices for DynamoDB and restrict developers and services running expensive Scan operations on tables. IAM is a fundamental control available to the users of Amazon Web Services. And it is essential to the AWS Well-Architected Framework.
Another security measure you can use is encryption in transit. It ensures that your data remains encrypted while moving between applications and DynamoDB tables. DynamoDB endpoints are accessible over HTTPS endpoints whether you use the AWS Management Console, AWS SDK, or CLI for DynamoDB.
10. Other bite-sized DynamoDB best practices
- Maintain as few tables as possible
It is a general rule of NoSQL design to maintain as few tables as possible. It will keep your DynamoDB database more scalable with fewer permissions management. Moreover, it reduces overhead for your database and helps keep backup costs lower.
- Use ‘DynamoDB Global Tables’ for latency-crucial applications
If latency is crucial for your application’s end-users, DynamoDB Global Tables can help. It automatically replicates data across multiple AWS Regions. Thus, it brings data closer to your end users.
For instance, Disney+ uses global tables for their Watchlist architecture and bookmarking service. It allowed them to deploy to any number of regions by adding that region to the DynamoDB global table.
- Try PartiQL
If your team has just started using Amazon DynamoDB, working with its unconventional query syntax may be challenging. For a SQL-like query language, your teams can try PartiQL.
- Use point-in-time recovery
Enable DynamoDB point-in-time backups and recovery before going live in production. So you can rollback your table in case of an error.
- Use TTL (time-to-live)
TTL allows you to remove expired items. It can be super useful for storing temporary data, such as session data, that consumes extra storage. The feature is entirely free and can help reduce storage costs.
When to use DynamoDB
Amazon DynamoDB is ideal for low-scale operations due to its simplicity. But it also shines at operating on an ultra-high scale, as demanded by Amazon.com. It powers many other powerful applications, including Snapchat, Zoom, Dropbox, and more. You should consider using DynamoDB for:
- Key-value or simple queries
- When high-performance reads and writes are required
- Auto-sharding
- Low latency applications
- High durability
- When no tuning is required
- When there are no size or throughput limits
- When you have scalability issues with other traditional database systems
- Online transaction processing (OLTP) workloads
- Mission-critical applications that must be highly available all the time without manual intervention
When not to use DynamoDB
Amazon DynamoDB may not be suitable for:
- Multi-item/row or cross-table transactions
- Complex queries and joins
- Real-time Analytics on historical data
- Services that need ad hoc query access
- Online analytical processing (OLAP) or data warehouse implementations
- Binary large object (BLOB) storage. However, blobs can be stored in Amazon S3 and its object pointers in a DynamoDB table.
How we used DynamoDB for a scalable EV charging platform?
When building FreeWire, one of the biggest challenges was processing millions of data points daily. So we followed a microservices design to improve performance and delivery under heavy loads.
To handle huge volumes of data, we used a mix of SQL and NoSQL database architecture. SQL database hosted on Amazon RDS performs database-level operations such as automated backup, creating replicas, etc. And DynamoDB is used to store and retrieve non-relational data.
Click here to read the full FreeWire case study
How Simform can help
DynamoDB’s scalability, flexibility, and serverless-friendly semantics make it a popular database choice among businesses today. But it must be modeled mindfully to ensure optimal performance and costs. However, the above list of best practices is not a definitive one.
At Simform, we architect cloud-native applications with best practices from years of experience working with AWS services, including DynamoDB. We are an AWS premier consulting partner, helping businesses in multiple verticals build powerful, futuristic applications. To work with our team of AWS-certified professionals, contact us today!




