
Observability-Driven Development: From Development to DevOps
Observability is understanding the internal states of a system by examining logs, metrics, and traces. It’s about being able to dig and investigate the entire picture from a new angle.
While the business value of observability is obvious>, adding observability to your system sounds like a difficult task. The outcomes, though, are worthwhile!
PhonePe, for example, was able to achieve a 2000% growth of data infrastructure and a 65% reduction in data management costs with a data observability solution. Observability helped PhonePe tackle issues affecting performance and causing unnecessary downtime.
This is just one case. There are many companies where observability-driven development (ODD) is making a massive impact. In fact, organizations with ODD are 2.1 times more likely to detect issues and report 69% better MTTR.
What is observability-driven development? (ODD)
Observability-driven development (ODD) is an approach to shift left observability to the earliest stage of the software development life cycle. It uses trace-based testing as a core part of the development process and simplifies complexities and management of the development lifecycle.
In ODD, developers write new code while declaring desired output and specifications that you need to view the system’s internal state and process. It applies both at a component level and as a whole system. ODD is also a function to standardize instrumentation. It can be across programming languages, frameworks, SDKs, and APIs.
Benefits of ODD
Observability-driven development (ODD) emerged out of the need to create modern systems that are easy to observe, analyze, and debug. Here are some business benefits of ODD:
- Faster resolution of incidents: With ODD, you can quickly identify and resolve issues before they become bigger problems. Airbnb has given us an example of an observability success story of detecting issues in their microservices architecture and resolving them before they impacted users.
- Improved system reliability: ODD helps improve system reliability by proactively monitoring and analyzing system performance. The high availability and performance of Netflix is a fine example of improved system reliability through ODD.
- Improved customer experience: ODD provides real-time visibility into the software system’s performance and behavior, allowing developers, operations, and business stakeholders to collaborate more effectively. For example, Twilio uses observability tools to ensure the high quality of their communication APIs, which enables their customers to deliver better user experiences.
- Reduced downtime and costs: ODD helps to detect issues early in the development cycle before they have a chance to cause significant downtime, thereby saving time and money spent on resolving those issues later on. Robinhood’s successful reduction in delivery time and increase in uptime were a result of efficient ODD processes.
- Increased innovation speed: ODD enables you to iterate and innovate quickly by providing visibility into system performance and behavior. Facebook is one of the companies that has remarkably accelerated the development and deployment of new features through ODD.
- Better decision-making: ODD provides valuable insights into system behavior and performance, which can inform better decision-making. For instance, Amazon uses observability tools to make data-driven decisions about optimizing its e-commerce platform for customer satisfaction and business performance.
In summary, observability-driven development provides several business benefits that can help organizations to reduce costs, innovate more quickly, improve customer satisfaction, and make better decisions.
Moving from TDD to observability in production
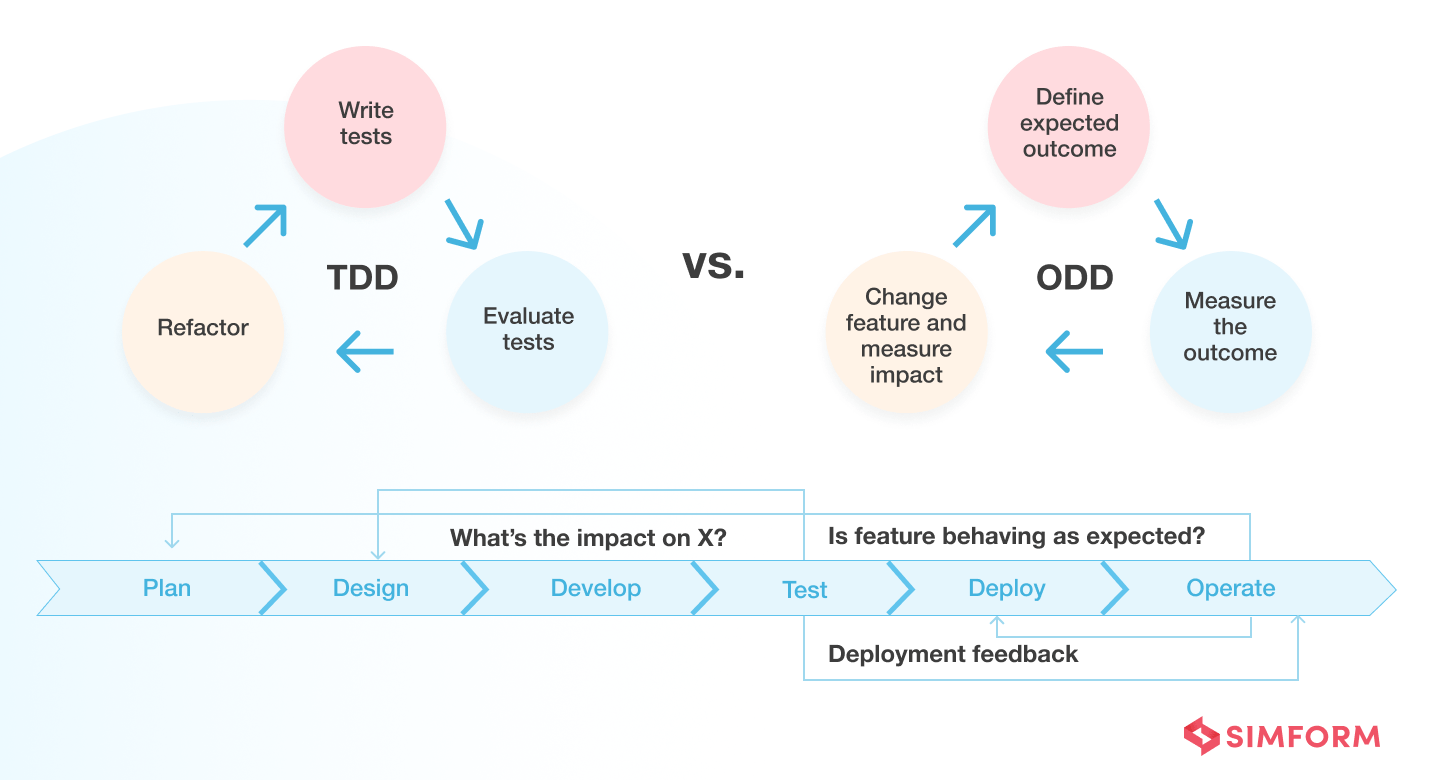
Is it a big deal to move your software development methodology from TDD to ODD? Well, yes! But why is it so?
For the last couple of decades, Test Driven Development (TDD) has been the gold standard for testing software before it goes into production for release.
TDD can run the same tests multiple times with accuracy and ensure consistency. However, these tests are in isolation. They can’t reveal how the entire application would work or whether your customer experience will be great or poor. In short, TDD doesn’t let you know what’s happening to your application inside the production.
Moreover, running successful tests through TDD doesn’t guarantee that there won’t be any errors when the app goes into production. It doesn’t have the mechanism to identify and fix the code before the application code before it gets live.
Lastly, TDD assumes a consistent production environment for conducting automated tests, which is not a real-time scenario. Experienced engineering managers or engineering teams would tell you that production environments are not consistent; it’s full of exciting deviations, and every test could create different anomalies. This means that TDD enables code traceability but doesn’t prepare for peculiarities you need to catch and test. It doesn’t allow you to know the real-time behavior and interaction of the app with its end users.
To overcome these issues, the phenomenon of observability comes onto the horizon. Observability is an evolved version of TDD that allows full-stack visibility into the infrastructure, application, and production area. It finds the root cause of issues affecting the user experience and product release through telemetry data such as logs, traces, and metrics. This continuous monitoring and tracking further help you develop a sense of predicability related to how end-users perceive the application.
Lastly, with Observability, you can write and ship better code even before it lands in source control—because it’s part of the set of tools, processes, and culture.
The role of observability in SDLC
Observability data primarily focuses on root cause analysis of the problem proactively. It covers unpredictable and predictable ways a service can fail, and alert software engineers.
Observability in the Software Development Life Cycle (SDLC) provides continuous feedback about the availability and performance of your application. It helps detect the “unknown unknowns” to understand better production incidents that impact app performance and customer experience.
With Observability tools, you can get answers to questions like
- From which component did an error originate?
- Where is latency being introduced?
- Which piece is taking up the most processing time?
- How is a buggy component affecting the entire ecosystem?
- At which level is the bug most prominent (code, platform, or architecture)?
As more teams are implementing DevOps and DevSecOps practices, the boundary between Observability and DevOps is blurring. It brings value to developers as they are involved in maintaining high availability, resilience, and app operability.
Observability in microservices
With various microservices distributed across different hosts, keeping track of dozens or even hundreds of microservices is challenging. These distributed systems can be potential points of failures and constant updates, which cannot be addressed by traditional system monitoring. Observability in microservices exposes system states in production so developers can detect and solve performance issues. It provides visibility and real-user monitoring to optimize the app’s performance and availability.
By implementing DevOps Research and Assessment and leveraging software intelligence platform, it is easy to curb large data volumes and latency and reliability related challenges for observability in microservices.
Here’s an example of Riot Games, a microservice architecture-based gaming platform. It adopted observability to detect and resolve critical issues affecting the gaming experience. The result is higher availability, better performance, and a more engaging fan experience.
Considerations for adopting ODD across various SDLC stages
ODD encourages a shift-left concept for observability right from the early phases of SDLC. This section will explore the high-level concerns you need to know for adopting ODD across various SDLC stages.
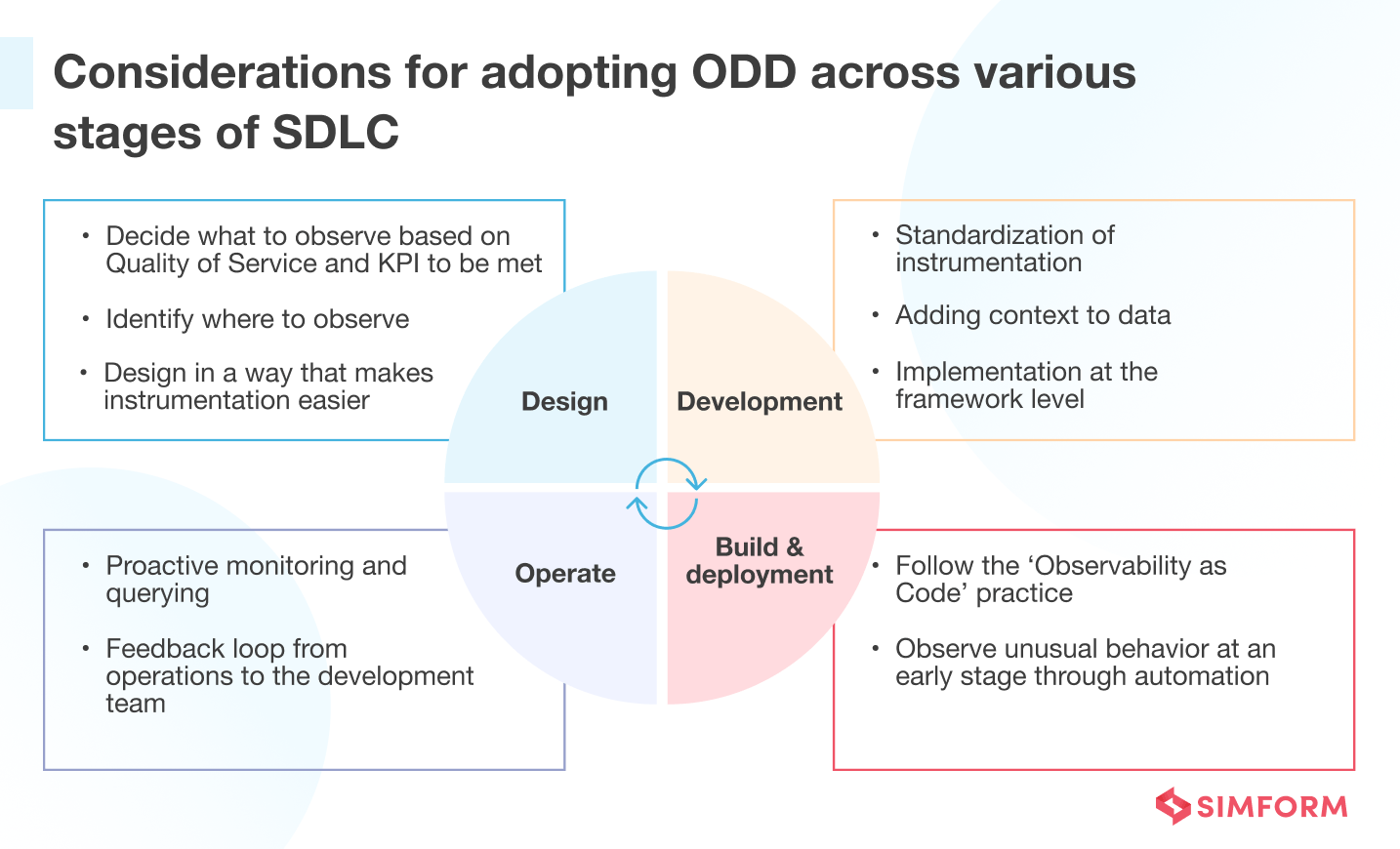
Design considerations
During the design phase, you must decide how the system will operate or which functionalities you want to perform. Based on this analysis, you can determine what points and processes to monitor and track continuously, which are critical data points to know system performance. For example, it could be MTTR (Mean Time to Repair), Average Response Time, Error Rate, Uptime, Downtime, Availability, etc.
Once you’ve identified the data points, you can know where to instrument. Observability in the design phase is about deciding where the instrumentation touchpoints would be so that you can accurately collect telemetry data from a container, service, application, host, etc, This will then help you know whether the system is working correctly or not.
Let us understand this with an example. Suppose you want to trace a particular event related to page load or average response time. You should design entry and exit points to get instrumentation data at a central location. Before diverging, entry or exit points should go through some standard code to handle specific functionalities. So, if you need to observe more components in the future, you can easily add them without refactoring the code.
Development considerations
Through the design phase, you’ve set up the instrumentation touchpoints through which you will get access to telemetry data. However, raw data without any context would be meaningless. So, during the development phase, provide context to the instrumentation data.
Build and deployment considerations
One of the practical implementation ways for observability during deployment is to follow the ‘Observability as Code’ practice. It’s a version that you can control and automate through deployment pipelines. In addition, it will ensure that observability gets implemented throughout the deployment environments.
Operation considerations
Operational observability allows you to conduct accurate debugging and proactive detection, improve the production system’s efficiency, and provide a holistic view of architecture.
So while implementing, the DevOps team should focus on proactive monitoring and a feedback loop from operations for continuous improvement. Prioritizing these actions would help you make your IT systems observable easily.
There are three ways to introduce operational observability into your organization:
- First, you can ask the BI team to set up SQL-based monitoring systems. It will send alerts to email addresses, and developers can take appropriate action.
- Second, you can develop a custom feature for monitoring and alerting that provides continuous data related to operations.
- Third, you can opt for operational observability software that sets up everything to make IT systems observable.
Standards and tooling considerations
Technology giants like Google and Facebook have adopted observability practices and developed tools/standards that can help you to develop the observable ecosystem. For example, Google has released OpenCensus, an open-source library for metric collection and tracing.
OpenTrace is another popular tool focused on distributed tracing developed by CNCF (Cloud Native Computing Foundation). Recently, OpenCensus and OpenTrace have agreed to merge their functionalities. They built a new tool called OpenTelemetry that combines structured logging, metrics, and tracing under one roof. TraceTest is one of the testing and tracing tools for microservice-based applications that takes its basis from OpenTelemetry.
In addition to all these tools, there are many Application Performance Monitoring (APM), log monitoring, and tracing tools that you can use according to your business requirements.
So, consider appropriate standard and also select a backend of your choice to store and visualize the tracing data for analysis.
How to integrate ODD into the IT ecosystem?
Integrating Observability-Driven Development (ODD) into the IT ecosystem requires a systematic approach that involves multiple steps. Here is a checklist of steps that organizations can follow to implement ODD:
- Define Metrics and SLOs: Establish clear metrics and Service Level Objectives (SLOs) that define the desired performance and reliability of the system.
- Implement Observability Tools: Invest in tools for logging, metrics, and tracing to capture project data on system behavior.
- Build a Monitoring Plan: Develop a monitoring plan that includes defining what to monitor, setting up alerts, and assigning responsibilities for handling issues.
- Collaborate Across Teams: Foster a culture of collaboration in the software development cycle, operations, and business stakeholders to ensure that the system meets the needs of all stakeholders.
- Prioritize Monitoring and Alerting: Make monitoring and alerting a priority, using data-driven insights to identify and address issues before they become critical.
- Embrace DevOps Practices: Implement DevOps practices emphasizing automation, collaboration, continuous improvement, and continuous delivery.
- Upskill Your Teams: Invest in training and upskilling your development teams to develop the necessary skills for ODD, including observability tools, DevOps practices, and data analysis.
By following this checklist, organizations can successfully integrate ODD into their IT ecosystem, enabling them to deliver reliable, scalable, and performant software that meets the needs of their customers.
A final note
Observability and instrumentation should not only be considered at the end of a development cycle. Try to embed them during each stage of SDLC and continually check whether the application you’re building will serve well to the users.
Observability will allow you to deliver the products with a greater level of confidence, while reducing the bridge between development and operations.
So, if you’re planning to incorporate observability in your IT ecosystem, we at SIMFORM can help make your IT systems observable by leveraging DevOps principles. Connect with our industry experts and find out how your business can reach new levels of success with observability.


