

 Databases on Kubernetes continue their rising trend. We see the growing adoption of our Percona Kubernetes Operators and the demand to migrate workloads to the cloud-native platform. Our Operators provide built-in backup and restore capabilities, but some users are still looking for old-fashioned ways, like storage-level snapshots (i.e., AWS EBS Snapshots).
Databases on Kubernetes continue their rising trend. We see the growing adoption of our Percona Kubernetes Operators and the demand to migrate workloads to the cloud-native platform. Our Operators provide built-in backup and restore capabilities, but some users are still looking for old-fashioned ways, like storage-level snapshots (i.e., AWS EBS Snapshots).
In this blog post, you will learn:
- How to back up and restore from storage snapshots using Percona Operators
- What the risks and limitations are of such backups
Overview
Volume Snapshots went GA in Kubernetes 1.20. Both your storage and Container Storage Interface (CSI) must support snapshots. All major cloud providers support them but might require some steps to enable it. For example, for GKE, you must create a VolumeSnapshotClass resource first.
At the high level, snapshotting on Kubernetes looks like this:
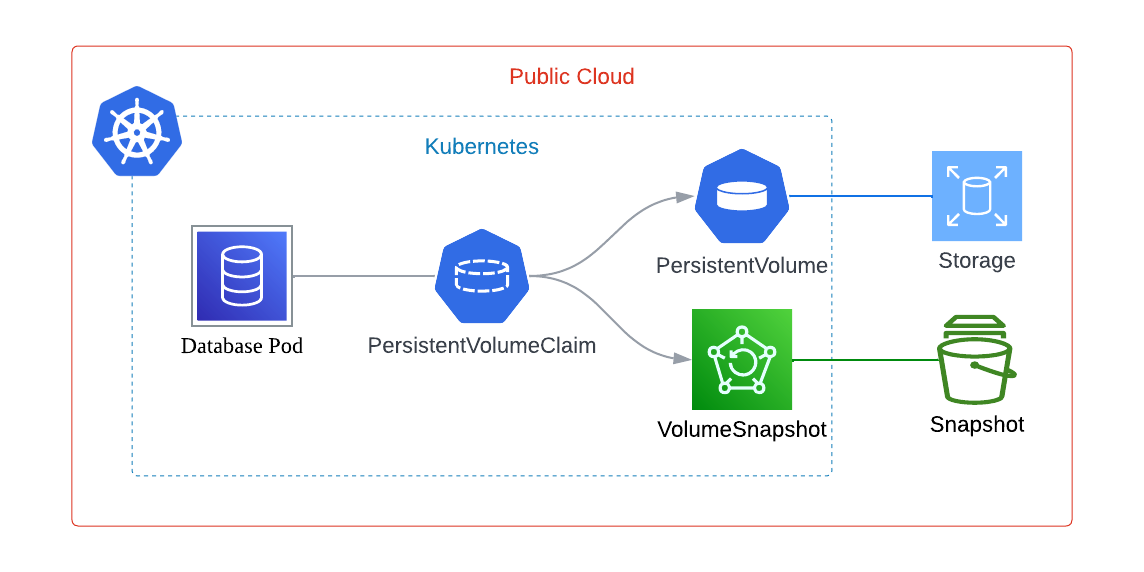
As PersistentVolume is represented by the real storage volume, VolumeSnapshot is the Kubernetes resource for volume snapshot in the cloud.
Getting ready for backups
First, we need to be sure that VolumeSnapshots are supported. For the major clouds, read the following docs:
- Google – Documentation on Volume Snapshots for GKE
- AWS – Using EBS Snapshots for persistent storage with your EKS cluster
- Azure – AKS CSI documentation
Once you have CSI configured and Volume Snapshot Class is in place, proceed to create a backup.
Take the backup
Identify the PersistentVolumeClaims (PVC) that you want to snapshot. For example, for my MongoDB cluster, I have six PVCs: three x replica set nodes and three x config server nodes.
1 2 3 4 5 6 7 8 | $ kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE mongod-data-my-cluster-name-cfg-0 Bound pvc-c9fb5afa-1fc9-41f9-88f3-4ed457f88e58 3Gi RWO standard-rwo 78m mongod-data-my-cluster-name-cfg-1 Bound pvc-b9253264-f79f-4fd0-8496-1d88105d84e5 3Gi RWO standard-rwo 77m mongod-data-my-cluster-name-cfg-2 Bound pvc-5d462005-4015-47ad-9269-c205b7a3dfcb 3Gi RWO standard-rwo 76m mongod-data-my-cluster-name-rs0-0 Bound pvc-410acf85-36ad-4bfc-a838-f311f9dfd40b 3Gi RWO standard-rwo 78m mongod-data-my-cluster-name-rs0-1 Bound pvc-a621dd8a-a671-4a35-bb3b-3f386550c101 3Gi RWO standard-rwo 77m mongod-data-my-cluster-name-rs0-2 Bound pvc-484bb835-0e2d-4a40-b5a3-1ba340ec0567 3Gi RWO standard-rwo 76m |
Each PVC will have its own VolumeSnapshot. Example for mongod-data-my-cluster-name-cfg-0:
1 2 3 4 5 6 7 8 | apiVersion: snapshot.storage.k8s.io/v1 kind: VolumeSnapshot metadata: name: mongod-data-my-cluster-name-cfg-0-snap spec: volumeSnapshotClassName: gke-snapshotclass source: persistentVolumeClaimName: mongod-data-my-cluster-name-cfg-0 |
I have listed all my VolumeSnapshots objects in one YAML manifest here.
1 2 3 4 5 6 7 | $ kubectl apply -f https://raw.githubusercontent.com/spron-in/blog-data/master/volume-snapshots/mongo-volumesnapshots.yaml volumesnapshot.snapshot.storage.k8s.io/mongod-data-my-cluster-name-cfg-0-snap created volumesnapshot.snapshot.storage.k8s.io/mongod-data-my-cluster-name-cfg-1-snap created volumesnapshot.snapshot.storage.k8s.io/mongod-data-my-cluster-name-cfg-2-snap created volumesnapshot.snapshot.storage.k8s.io/mongod-data-my-cluster-name-rs0-0-snap created volumesnapshot.snapshot.storage.k8s.io/mongod-data-my-cluster-name-rs0-1-snap created volumesnapshot.snapshot.storage.k8s.io/mongod-data-my-cluster-name-rs0-2-snap created |
VolumeSnapshotContent is created and bound to every VolumeSnapshot resource. Its status can tell you the name of the snapshot in the cloud and check if a snapshot is ready:
1 2 3 4 5 6 7 | $ kubectl get volumesnapshotcontent snapcontent-0e67c3b5-551f-495b-b775-09d026ea3c8f -o yaml … status: creationTime: 1673260161919000000 readyToUse: true restoreSize: 3221225472 snapshotHandle: projects/percona-project/global/snapshots/snapshot-0e67c3b5-551f-495b-b775-09d026ea3c8f |
- snapshot-0e67c3b5-551f-495b-b775-09d026ea3c8f is the snapshot I have in GCP for the volume.
- readyToUse: true – indicates that the snapshot is ready
Restore
The restoration process, in a nutshell, looks as follows:
- Create persistent volumes using the snapshots. The names of the volumes must match the standard that Operator uses.
- Provision the cluster
Like any other backup, it must have secrets in place: TLS and users.
You can use this restoration process to clone existing clusters as well, just make sure you change the cluster, PVCs, and Secret names.
Create persistent volumes from snapshots. It is the same as the creation of regular PersistentVolumeClaim, but with a dataSource section that points to the snapshot:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | apiVersion: v1 kind: PersistentVolumeClaim metadata: name: mongod-data-my-cluster-name-rs0-0 spec: dataSource: name: mongod-data-my-cluster-name-rs0-0-snap kind: VolumeSnapshot apiGroup: snapshot.storage.k8s.io storageClassName: standard-rwo accessModes: - ReadWriteOnce resources: requests: storage: 3Gi $ kubectl apply -f https://raw.githubusercontent.com/spron-in/blog-data/master/volume-snapshots/mongo-pvc-restore.yaml persistentvolumeclaim/mongod-data-my-cluster-name-cfg-0 created persistentvolumeclaim/mongod-data-my-cluster-name-cfg-1 created persistentvolumeclaim/mongod-data-my-cluster-name-cfg-2 created persistentvolumeclaim/mongod-data-my-cluster-name-rs0-0 created persistentvolumeclaim/mongod-data-my-cluster-name-rs0-1 created persistentvolumeclaim/mongod-data-my-cluster-name-rs0-2 created |
Once done, spin up the cluster as usual. The volumes you created earlier will be used automatically. Restoration is done.
Risks and limitations
Storage support
Both storage and the storage plugin in Kubernetes must support volume snapshots. This limits the choices. Apart from public clouds, there are open source solutions like Ceph (rook.io for k8s) that can provide snapshotting capabilities.
Point-in-time recovery
Point-in-time recovery (PITR) allows you to reduce your Point Recovery Objective by restoring or rolling back the database to a specific transaction or time.
Volume snapshots in the clouds store data in increments. The first snapshot holds all the data, and the following ones only store the changes. This significantly reduces your cloud bill. But snapshots cannot provide you with the same RPO as native database mechanisms.
Data consistency and corruption
Snapshots are not data-aware. When a snapshot is taken, numerous transactions and data modifications can happen. For example, heavy write activity and simultaneous compound index creation in MongoDB might lead to snapshot corruption. The biggest problem is that you will learn about data corruption during restoration.
Locking or freezing a filesystem before the snapshot would help to avoid such issues. Solutions like Velero or Veeam make the first steps towards data awareness and can create consistent snapshots by automating file system freezes or stopping replication.
Percona Services teams use various tools to automate the snapshot creation safely. Please contact us here to ensure data safety.
Cost
Public clouds store snapshots on cheap object storage but charge you extra for convenience. For example, the AWS EBS snapshot is priced at $0.05/GB, whereas S3 is only $0.023. It is a 2x difference, which for giant data sets might significantly increase your bill.
Time to recover
It is not a risk or limitation but a common misconception I often see: recovery from snapshots takes only a few seconds. It does not. When you create an EBS volume from the snapshot, it takes a few seconds. But in reality, the volume you just created does not have any data. You can read more about the internals of EBS snapshots in this nice blog post.
Conclusion
Volume Snapshots on Kubernetes can be used for databases but come with certain limitations and risks. Data safety and consistency are the most important factors when choosing a backup solution. For Percona Operators, we strongly recommend using built-in solutions which guarantee data consistency and minimize your recovery time and point objectives.
Learn More About Percona Kubernetes Operators





