

Kubernetes for Big Data Workloads
Abhishek Tiwari
DECEMBER 27, 2017
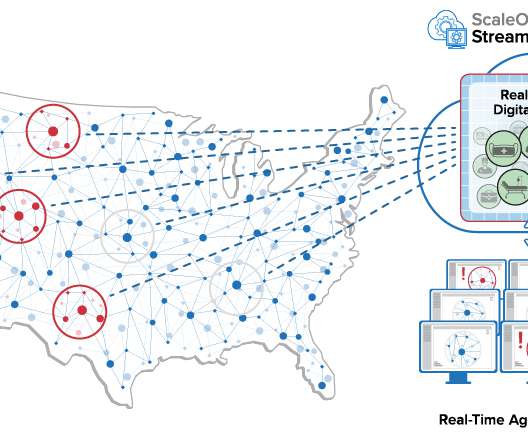
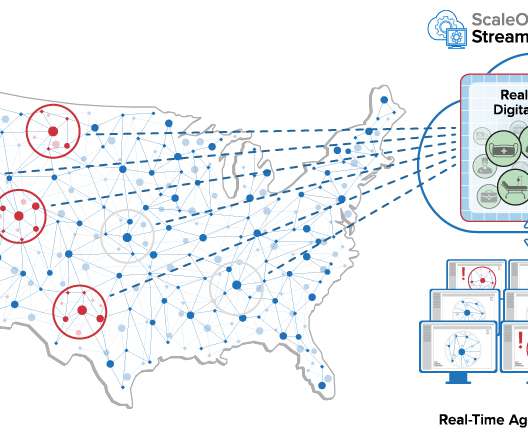
Kubernetes has emerged as go to container orchestration platform for data engineering teams. In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Storage provisioning.








































Let's personalize your content