
In today’s data-driven landscape, businesses are grappling with an unprecedented surge in data volume. The rise of cloud-native microservice architectures further exacerbates this change. The data generated by applications to support operational teams has reached overwhelming proportions. This data overload also prevents customer-centric pricing models as users consider cost-effective technology platforms.
Over the past decade, observability vendors have built cost models that have not accounted for the explosive rise in data required by customers. These cost models remain firmly rooted in outdated IT paradigms ill-equipped to handle the data deluge modern enterprises face.
This situation has business consequences. Customers are forced to shoulder the direct costs of these antiquated models, stifling their ability to thrive in an era where data is the lifeblood of success. One workaround customers take is sampling critical data to manage ingestion cost. This leaves customers at a disadvantage with not having all the data needed to troubleshoot issues quickly. What stands out as an imperative now is the urgent need for vendors to shift their focus back to customers and resist the temptation to capitalize on the growing demand for extensive data management and monitoring in complex IT environments.
Achieving customer-centric pricing: Answer-centric vs. ingest-centric pricing
Today’s observability market primarily offers two pricing models: ingest-centric and answer-centric.
Ingest-centric pricing is an outdated model that transfers the cost of data ingestion and data retention directly to customers. This pricing model adversely affects customers in several ways. Customers experience delayed time to value from the data they’re ingesting as they must take additional steps to make the data useful for troubleshooting and analysis, such as re-indexing. This approach is wasteful because customers are charged for indexing terabytes of unused data then charged again to re-index the data for additional analysis. Moreover, the system lacks flexibility, imposing strict schemas that administrators and developers must adhere to avoid additional costs. Customers find themselves confined to models that limit their ability to leverage the volume of data they possess for practical analysis. As a result, IT organizations are overwhelmed as they strive to balance cost control processes with ensuring that their respective organizations have access to all the data required for their various use cases.
In contrast, answer-centric pricing simply charges customers when they query data. The Dynatrace pricing model available with Log Management and Analytics platform entails minimal charges for data ingestion and retention. The majority of costs are associated with data querying.
Dynatrace has developed the purpose-built data lakehouse, Grail, eliminating the need for separate management of indexes and storage. All data is readily accessible without storage tiers, such as costly solid-state drives (SSDs). With Dynatrace, you only pay for what you use.
With the Dynatrace cost model, the majority of the expenses shift from data ingestion to querying. We offer our customers an adaptable data platform capable of comprehending every data format, enabling immediate access without needing high-cost storage tiers. Grail is designed for scalability, with no technical prerequisites or additional hosting and storage costs as ingestion rates increase. Lastly, Davis® AI swiftly provides answers at any scale, effectively addressing IT operations teams’ data management challenges.
A prominent U.S. retail giant, initially tied to an ingest-centric pricing vendor, found itself manually curbing costs by limiting daily log ingestion to 3 TB and reducing retention periods. Consequently, the company’s mean time to identify (MTTI) and mean time to resolve (MTTR) during peak retail seasons was too slow. Slow reaction times, in turn, caused failed customer transactions. As a result, the company awarded customers gift cards for system failures, creating an additional cost. Conversely, with a customer-centric pricing approach, the company could focus on getting answers from its data rather than trying to curb log ingestion to avoid price hikes on its observability platform.
They chose Dynatrace’s answer-centric pricing model and migrated off their previous ingest-centric vendor. Here are their business and technical results with Dynatrace:
- MTTI and root-causes analysis time was reduced by 80%. Swiftly identifying and resolving issues, even during high-demand periods, became the new norm.
- Increased data ingestion at reduced costs. The company’s data ingestion capacity skyrocketed from 3TB per day to an impressive 30 TB daily, all at a reduced price.
- Enhanced code-level visibility. Dynatrace provided invaluable code-level visibility into issues, leading to faster MTTR.
- Streamlined log analysis with Davis® AI: Automating log analysis via Davis® AI slashed analysis time from 45 minutes to a mere 5 seconds per instance, rendering manual troubleshooting obsolete.
- $1 million in savings. By migrating 95% of its log data away from the ingest-centric pricing vendor, the retailer realized substantial savings, totaling $1 million.
This compelling success story underscores how the Dynatrace customer-centric pricing approach can drive efficiency, cost savings, and performance improvements for businesses in any sector when using Log Management and Analytics platform.
Don’t you think it’s time to stop paying a premium for data you don’t use?
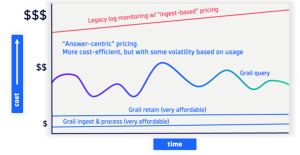
What is the ingest, retain, and query pricing model?
With the new Dynatrace pricing model available on Log Management and Analytics platform for ingest and process, retain, and query, you always pay for your actual usage based on the value you get from the data.
- Ingest and process. This phase covers bringing your data into Dynatrace software as a service (SaaS) via whichever ingestion channel or method. You can use the generic ingest with an application programming interface (API) endpoint to point existing log output to Dynatrace, ingest OpenTelemetry logs, or deploy our OneAgent, which discovers important logs automatically and sends them to Dynatrace. This step also includes purchasing an additional tool and maintaining it. As logs always come in different formats, processing lets you normalize them, select or extract relevant fields, manipulate any attribute or field, mask sensitive data, or do mathematical calculations on ingest (for example, auto-sum all the items placed in a shopping cart, as reflected in the log event).
- Retain. It’s simple and clear to pay only for the days you need to keep your data and not succumb to some unnecessary default. But the hidden power of retaining data with Dynatrace is how simple it is always to access that data. As long as it’s retained, the data is always at your fingertips, with zero management needed. No storage tiers, no archiving or retrieval from archives, and no indexing or reindexing.
- Query. The power of answer-centric pricing means you’ll pay for querying only the data you need. Do you need to keep some data stored for business continuity, compliance, or other reasons, but you don’t access it? Then, your query cost for that data is also zero.
What is the value of the ingest, retain, and query pricing model?
Dynatrace is upfront and clear on what customers pay for. For ingest and process, you pay per gibibyte; for retaining data, you pay for gibibyte retained per day; for querying, you pay per gibibyte scanned. We’re customer-centric in that the bytes customers are charged for reflect actual data usage. There are no extra fees or hidden costs. Ingest-centric pricing vendors charge for additional add-ons, plug-ins, monthly commitments, and penalties for breaking monthly commitments, in addition to varying hidden charges for peak usage vs. average usage cost. Dynatrace is clear about our customer-centric commitment to only charge for data used.
Pricing the actual usage is integral to the financial accountability with the cloud architecture variable spend model. Cloud usage has inherent volatility as a company rolls out products and services, enables new features and versions, onboards new users, and allows the existing customer base to expand its usage, ultimately generating revenue. As a company migrates from the traditional data center model to cloud architecture, this pricing per byte is tightly coupled with your business success.
Easing the transition to self-governance
Although pricing ingest, retain, and query align with the cloud spend model and thus customer success, it can be challenging to adopt initially. We know how teams from the traditional data center model say it takes time to readjust to this new model, even though they later claim how much fairer and better the model is.
To support such a transition, we built numerous in-product guardrails that give you peace of mind from accidental usage. For example, this includes the following:
- Click to query. While you configure your simple point-and-click query or write an advanced Dynatrace Query Language (DQL) statement, you’ll always stay in control of executing the query.
- Cancel any time. Erroneous clicks or changing one’s mind should not require a running query to cost the total amount. This means teams can always cancel a running query.
- Suggest alternatives. DQL offers many options for analyzing logs, such as extracting metrics from historical data and charting or visualizing them. But if teams want to pin a query to a dashboard for use in day-to-day operations, there may be a better tool. While DQL is best for exploratory analytics, extracting log metrics during ingest and placing them on a dashboard has better performance and cost for you.
- Transparency. If pricing includes queried gigabytes, you should always see and understand how many bytes that query included. Beware, you might be surprised how cost-efficient most of the queries are!
- Smart defaults. You can set up automatically running queries, for example, if required. But by default, the automatic refresh of queries is off.
- Start step-by-step with DQL. Whether you explore DQL in an app such as Learn DQL, look at the best practices, or make the first queries on your data, you’re guided by default parameters and commands that always keep you in control.

These and other product design details guide each user as he or she operates Dynatrace. As an admin, you can support this on an environment level with the right approach to the core technologies.
When adopting Grail for observability or business data, for example, follow the best practices for data management with Grail bucket assignment. This helps separate use cases, provide data segmentation for teams or business units, set up basic access control measures, and optimize Grail query performance. As a next step, you can set up more fine-grained access policies, which not only enforce your access controls but also make onboarding users easier as they can’t query wrong data even by mistake. Read more about Grail buckets and access policies from this blog.
Following user- and environment-level features, teams can make the most of the new account management tooling. Dynatrace Platform Subscription customers get complete cost transparency with the Account Management portal, which enables them to monitor spend setup notifications for anomalies with cost alerting. When you include proactive smart forecasting, you are monitoring past usage and what’s happening today and can make decisions about the future.

Customer-centric pricing for today’s data-driven landscape
Dynatrace continues to advance customer-first innovations, addressing the explosive data growth and the associated cost of managing at scale with our Log Management and Analytics Platform. Customer-centric pricing, which focuses on garnering data from answers rather than pricing based on data ingestion, is the latest advancement in the Dynatrace platform.
For more information on Dynatrace Platform Subscription (DPS), please visit here. If you’re a Dynatrace customer today, please talk with your account team to consider DPS for your current modules in use.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum