Real-Real-World Programming with ChatGPT
Taking AI Far Beyond Small Self-Contained Coding Tasks
 Binary world (source: Pixabay)
Binary world (source: Pixabay)
If you’re reading this, chances are you’ve played around with using AI tools like ChatGPT or GitHub Copilot to write code for you. Or even if you haven’t yet, then you’ve at least heard about these tools in your newsfeed over the past year. So far I’ve read a gazillion blog posts about people’s experiences with these AI coding assistance tools. These posts often recount someone trying ChatGPT or Copilot for the first time with a few simple prompts, seeing how it does for some small self-contained coding tasks, and then making sweeping claims like “WOW this exceeded all my highest hopes and wildest dreams, it’s going to replace all programmers in five years!” or “ha look how incompetent it is … it couldn’t even get my simple question right!”
I really wanted to go beyond these quick gut reactions that I’ve seen so much of online, so I tried using ChatGPT for a few weeks to help me implement a hobby software project and took notes on what I found interesting. This article summarizes what I learned from that experience. The inspiration (and title) for it comes from Mike Loukides’ Radar article on Real World Programming with ChatGPT, which shares a similar spirit of digging into the potential and limits of AI tools for more realistic end-to-end programming tasks.

Learn faster. Dig deeper. See farther.
Setting the Stage: Who Am I and What Am I Trying to Build?
I’m a professor who is interested in how we can use LLMs (Large Language Models) to teach programming. My student and I recently published a research paper on this topic, which we summarized in our Radar article Teaching Programming in the Age of ChatGPT. Our paper reinforces the growing consensus that LLM-based AI tools such as ChatGPT and GitHub Copilot can now solve many of the small self-contained programming problems that are found in introductory classes. For instance, problems like “write a Python function that takes a list of names, splits them by first and last name, and sorts by last name.” It’s well-known that current AI tools can solve these kinds of problems even better than many students can. But there’s a huge difference between AI writing self-contained functions like these and building a real piece of software end-to-end. I was curious to see how well AI could help students do the latter, so I wanted to first try doing it myself.
I needed a concrete project to implement with the help of AI, so I decided to go with an idea that had been in the back of my head for a while now: Since I read a lot of research papers for my job, I often have multiple browser tabs open with the PDFs of papers I’m planning to read. I thought it would be cool to play music from the year that each paper was written while I was reading it, which provides era-appropriate background music to accompany each paper. For instance, if I’m reading a paper from 2019, a popular song from that year could start playing. And if I switch tabs to view a paper from 2008, then a song from 2008 could start up. To provide some coherence to the music, I decided to use Taylor Swift songs since her discography covers the time span of most papers that I typically read: Her main albums were released in 2006, 2008, 2010, 2012, 2014, 2017, 2019, 2020, and 2022. This choice also inspired me to call my project Swift Papers.
Swift Papers felt like a well-scoped project to test how well AI handles a realistic yet manageable real-world programming task. Here’s how I worked on it: I subscribed to ChatGPT Plus and used the GPT-4 model in ChatGPT (first the May 12, 2023 version, then the May 24 version) to help me with design and implementation. I also installed the latest VS Code (Visual Studio Code) with GitHub Copilot and the experimental Copilot Chat plugins, but I ended up not using them much. I found it easier to keep a single conversational flow within ChatGPT rather than switching between multiple tools. Lastly, I tried not to search for help on Google, Stack Overflow, or other websites, which is what I would normally be doing while programming. In sum, this is me trying to simulate the experience of relying as much as possible on ChatGPT to get this project done.
Getting Started: Setup Trials and Tribulations
Here’s the exact prompt I used to start my conversation with ChatGPT using GPT-4:
Act as a software developer to help me build something that will play music from a time period that matches when an academic paper I am reading in the browser was written.
I purposely kept this prompt high-level and underspecified since I wanted ChatGPT to guide me toward design and implementation ideas without me coming in with preconceived notions.
ChatGPT immediately suggested a promising direction—making a browser extension that gets the date of the research paper PDF in the currently-active tab and calls a music streaming API to play a song from that time period. Since I already had a YouTube Music account, I asked whether I could use it, but ChatGPT said that YouTube Music doesn’t have an API. We then brainstormed alternative ideas like using a browser automation tool to programmatically navigate and click on parts of the YouTube Music webpage. ChatGPT gave me some ideas along these lines but warned me that, “It’s important to note that while this approach doesn’t use any official APIs, it’s more brittle and more subject to break if YouTube Music changes their website structure. […] keep in mind that web scraping and browser automation can be complex, and handling all of the edge cases can be a significant amount of work. […] using APIs might be a more reliable and manageable solution.” That warning convinced me to drop this idea. I recalled that ChatGPT had recommended the Spotify Web API in an earlier response, so I asked it to teach me more about what it can do and tell me why I should use it rather than YouTube Music. It seemed like Spotify had what I needed, so I decided to go with it. I liked how ChatGPT helped me work through the tradeoffs of these initial design decisions before diving head-first into coding.
Next we worked together to set up the boilerplate code for a Chrome browser extension, which I’ve never made before. ChatGPT started by generating a manifest.json file for me, which holds the configuration settings that every Chrome extension needs. I didn’t know it at the time, but manifest.json would cause me a bunch of frustration later on. Specifically:
- ChatGPT generated a manifest.json file in the old Version 2 (v2) format, which is unsupported in the current version of Chrome. For a few years now Google has been transitioning developers to v3, which I didn’t know about since I had no prior experience with Chrome extensions. And ChatGPT didn’t warn me about this. I guessed that maybe ChatGPT only knew about v2 since it was trained on open-source code from before September 2021 (its knowledge cutoff date) and v2 was the dominant format before that date. When I tried loading the v2 manifest.json file into Chrome and saw the error message, I told ChatGPT “Google says that manifest version 2 is deprecated and to upgrade to version 3.” To my surprise, it knew about v3 from its training data and generated a v3 manifest file for me in response. It even told me that v3 is the currently-supported version (not v2!) … yet it still defaulted to v2 without giving me any warning! This frustrated me even more than if ChatGPT had not known about v3 in the first place (in that case I wouldn’t blame it for not telling me something that it clearly didn’t know). This theme of sub-optimal defaults will come up repeatedly—that is, ChatGPT ‘knows’ what the optimal choice is but won’t generate it for me without me asking for it. The dilemma is that someone like me who is new to this area wouldn’t even know what to ask for in the first place.
- After I got the v3 manifest working in Chrome, as I tried using ChatGPT to help me add more details to my manifest.json file, it tended to “drift” back to generating code in v2 format. I had to tell it a few times to only generate v3 code from now on, and I still didn’t fully trust it to follow my directive. Besides generating code for v2 manifest files, it also generated starter JavaScript code for my Chrome extension that works only with v2 instead of v3, which led to more mysterious errors. If I were to start over knowing what I do now, my initial prompt would have sternly told ChatGPT that I wanted to make an extension using v3, which would hopefully avoid it leading me down this v2 rabbit hole.
- The manifest file that ChatGPT generated for me declared the minimal set of permissions—it only listed the activeTab permission, which grants the extension limited access to the active browser tab. While this has the benefit of respecting user privacy by minimizing permissions (which is a best practice that ChatGPT may have learned from its training data), it made my coding efforts a lot more painful since I kept running into unexpected errors when I tried adding new functionality to my Chrome extension. Those errors often showed up as something not working as intended, but Chrome wouldn’t necessarily display a permission denied message. In the end, I had to add four additional permissions—”tabs”, “storage”, “scripting”, “identity”—as well as a separate “host_permissions” field to my manifest.json.
Wrestling with all these finicky details of manifest.json before I could begin any real coding felt like death by a thousand cuts. In addition, ChatGPT generated other starter code in the chat, which I copied into new files in my VS Code project:
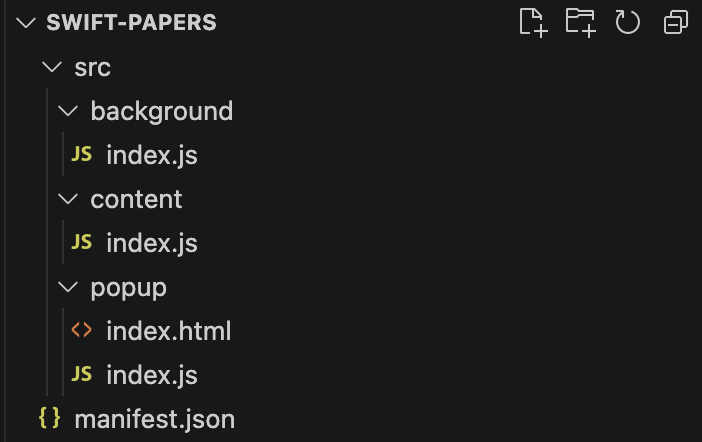
Intermission 1: ChatGPT as a Personalized Tutor
As shown above, a typical Chrome extension like mine has at least three JavaScript files: a background script, a content script, and a pop-up script. At this point I wanted to learn more about what all these files are meant to do rather than continuing to obediently copy-paste code from ChatGPT into my project. Specifically, I discovered that each file has different permissions for what browser or page components it can access, so all three must coordinate to make the extension work as intended. Normally I would read tutorials about how this all fits together, but the problem with tutorials is that they are not customized to my specific use case. Tutorials provide generic conceptual explanations and use made-up toy examples that I can’t relate to. So I end up needing to figure out how their explanations may or may not apply to my own context.
In contrast, ChatGPT can generate personalized tutorials that use my own Swift Papers project as the example in its explanations! For instance, when it explained to me what a content script does, it added that “For your specific project, a content script would be used to extract information (the publication date) from the academic paper’s webpage. The content script can access the DOM of the webpage, find the element that contains the publication date, and retrieve the date.” Similarly, it taught me that “Background scripts are ideal for handling long-term or ongoing tasks, managing state, maintaining databases, and communicating with remote servers. In your project, the background script could be responsible for communicating with the music API, controlling the music playback, and storing any data or settings that need to persist between browsing sessions.”
I kept asking ChatGPT follow-up questions to get it to teach me more nuances about how Chrome extensions worked, and it grounded its explanations in how those concepts applied to my Swift Papers project. To accompany its explanations, it also generated relevant example code that I could try out by running my extension. These explanations clicked well in my head because I was already deep into working on Swift Papers. It was a much better learning experience than, say, reading generic getting-started tutorials that walk through creating example extensions like “track your page reading time” or “remove clutter from a webpage” or “manage your tabs better” … I couldn’t bring myself to care about those examples since THEY WEREN’T RELEVANT TO ME! At the time, I cared only about how these concepts applied to my own project, so ChatGPT shined here by generating personalized mini-tutorials on-demand.
Another great side-effect of ChatGPT teaching me these concepts directly within our ongoing chat conversation is that whenever I went back to work on Swift Papers after a few days away from it, I could scroll back up in the chat history to review what I recently learned. This reinforced the knowledge in my head and got me back into the context of resuming where I last left off. To me, this is a huge benefit of a conversational interface like ChatGPT versus an IDE autocomplete interface like GitHub Copilot, which doesn’t leave a trace of its interaction history. Even though I had Copilot installed in VS Code as I was working on Swift Papers, I rarely used it (beyond simple autocompletions) since I liked having a chat history in ChatGPT to refer back to in later sessions.
Next Up: Choosing and Installing a Date Parsing Library
Ideally Swift Papers would infer the date when an academic paper was written by analyzing its PDF file, but that seemed too hard to do since there isn’t a standard place within a PDF where the publication date is listed. Instead what I decided to do was to parse the “landing pages” for each paper that contains metadata such as its title, abstract, and publication date. Many papers I read are linked from a small handful of websites, such as the ACM Digital Library, arXiv, or Google Scholar, so I could parse the HTML of those landing pages to extract publication dates. For instance, here’s the landing page for the classic Beyond being there paper:
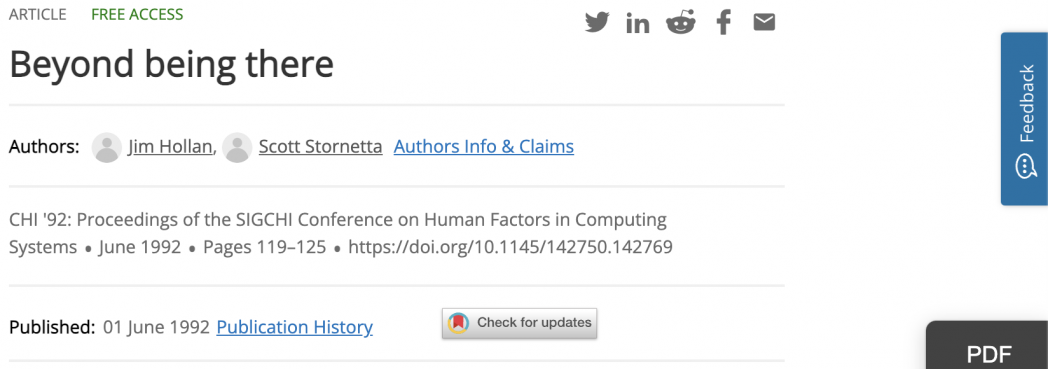
I wanted to parse the “Published: 01 June 1992” string on that page to get 1992 as the publication year. I could’ve written this code by hand, but I wanted to try using a JavaScript date parsing library since it would be more robust to date format variations that appear on various websites (e.g., using “22” for the year 2022). Also, since any real-world software project will need to use external libraries, I wanted to see how well ChatGPT could help me choose and install libraries.
ChatGPT suggested two libraries for me: Moment.js and chrono-node. However, it warned me about Moment.js: “as of September 2020, it is considered a legacy project and not recommended for new projects as the team is not planning on doing any new development or maintenance.” I verified this was true by seeing the same warning on the Moment.js homepage. But still, I liked how Moment.js was available as a single self-contained file that I could directly include into my extension without using a package manager like npm or a bundler like webpack (the fewer external tools I needed to set up, the better!). Or so I thought … ChatGPT led me to believe that I could get by without npm and webpack, but later I discovered that this only works in the old Manifest v2 extension format that is no longer supported by Chrome. It turns out that with Manifest v3, all external libraries must be bundled together using tools like npm and webpack in order for the extension to import them. So it goes… once more I got bitten by the fact that ChatGPT was biased toward producing outdated information for v2 rather than the newer v3, presumably because there was a lot more information about v2 in its training data.
Since I had to use npm and webpack anyways, I decided to go with chrono-node since it seemed more robust and up-to-date (no pun intended). I had ChatGPT help me set up my webpack configuration file (webpack.config.js) and things almost seemed to work, except that I got a mysterious error. When I pasted the error message into ChatGPT, it correctly diagnosed the problem, which was something related to (surprise surprise!) webpack’s default settings not being compatible with the security restrictions of my extension’s Manifest v3 format. It also suggested a working fix to webpack.config.js:
This error message is related to the Content Security Policy (CSP) of Chrome extensions. […] By default, Manifest V3 disallows the use of
eval()and theFunction()constructor, which are typically used for evaluating or creating code from strings […] Webpack, by default, includes a small amount of inline JavaScript code for handling hot module replacement and some other features. This code useseval()which is not allowed in the context of a Chrome extension. To solve this, you can adjust your webpack configuration to output code in a format that doesn’t rely oneval(). In your webpack.config.js, you can set the devtool option to ‘none’ or use the ‘source-map’ setting […]
Here again ChatGPT showed me that it clearly knew what the problem was (since it told me after I fed it the error message!) and how to fix it. So why didn’t it produce the correct webpack configuration file in the first place?
More generally, several times I’ve seen ChatGPT produce code that I felt might be incorrect. Then when I tell it that there might be a bug in a certain part, it admits its mistake and produces the correct code in response. If it knew that its original code was incorrect, then why didn’t it generate the correct code in the first place?!? Why did I have to ask it to clarify before it admitted its mistake? I’m not an expert at how LLMs work internally, but my layperson guess is that it may have to do with the fact that ChatGPT generates code linearly one token at a time, so it may get ‘stuck’ near local maxima (with code that mostly works but is incorrect in some way) while it is navigating the enormous abstract space of possible output code tokens; and it can’t easily backtrack to correct itself as it generates code in a one-way linear stream. But after it finishes generating code, when the user asks it to review that code for possible errors, it can now “see” and analyze all of that code at once. This comprehensive view of the code may enable ChatGPT to find bugs better, even if it couldn’t avoid introducing those bugs in the first place due to how it incrementally generates code in a one-way stream. (This isn’t an accurate technical explanation, but it’s how I informally think about it.)
Intermission 2: ChatGPT as a UX Design Consultant
Now that I had a basic Chrome extension that could extract paper publication dates from webpages, the next challenge was using the Spotify API to play era-appropriate Taylor Swift songs to accompany these papers. But before embarking on another coding-intensive adventure, I wanted to switch gears and think more about UX (user experience). I got so caught up in the first few hours of getting my extension set up that I hadn’t thought about how this app ought to work in detail. What I needed at this time was a UX design consultant, so I wanted to see if ChatGPT could play this role.
Note that up until now I had been doing everything in one long-running chat session that focused on coding-related questions. That was great because ChatGPT was fully “in the zone” and had a very long conversation (spanning several hours over multiple days) to use as context for generating code suggestions and technical explanations. But I didn’t want all that prior context to influence our UX discussion, so I decided to begin again by starting a brand-new session with the following prompt:
You are a Ph.D. graduate in Human-Computer Interaction and now a senior UX (user experience) designer at a top design firm. Thus, you are very familiar with both the experience of reading academic papers in academia and also designing amazing user experiences in digital products such as web applications. I am a professor who is creating a Chrome Extension for fun in order to prototype the following idea: I want to make the experience of reading academic papers more immersive by automatically playing Taylor Swift songs from the time period when each paper was written while the reader is reading that particular paper in Chrome. I have already set up all the code to connect to the Spotify Web API to programmatically play Taylor Swift songs from certain time periods. I have also already set up a basic Chrome Extension that knows what webpages the user has open in each tab and, if it detects that a webpage may contain metadata about an academic paper then it parses that webpage to get the year the paper was written in, in order to tell the extension what song to play from Spotify. That is the basic premise of my project.
Your job is to serve as a UX design consultant to help me design the user experience for such a Chrome Extension. Do not worry about whether it is feasible to implement the designs. I am an experienced programmer so I will tell you what ideas are or are not feasible to implement. I just want your help with thinking through UX design.
As our session progressed, I was very impressed with ChatGPT’s ability to help me brainstorm how to handle different user interaction scenarios. That said, I had to give it some guidance upfront using my knowledge of UX design: I started by asking it to come up with a few user personas and then to build up some user journeys for each. Given this initial prompting, ChatGPT was able to help me come up with practical ideas that I didn’t originally consider all too well, especially for handling unusual edge cases (e.g., what should happen to the music when the user switches between tabs very quickly?). The back-and-forth conversational nature of our chat made me feel like I was talking to a real human UX design consultant.
I had a lot of fun working with ChatGPT to refine my initial high-level ideas into a detailed plan for how to handle specific user interactions within Swift Papers. The culmination of our consulting session was ChatGPT generating ASCII diagrams of user journeys through Swift Papers, which I could later refer to when implementing this logic in code. Here’s one example:
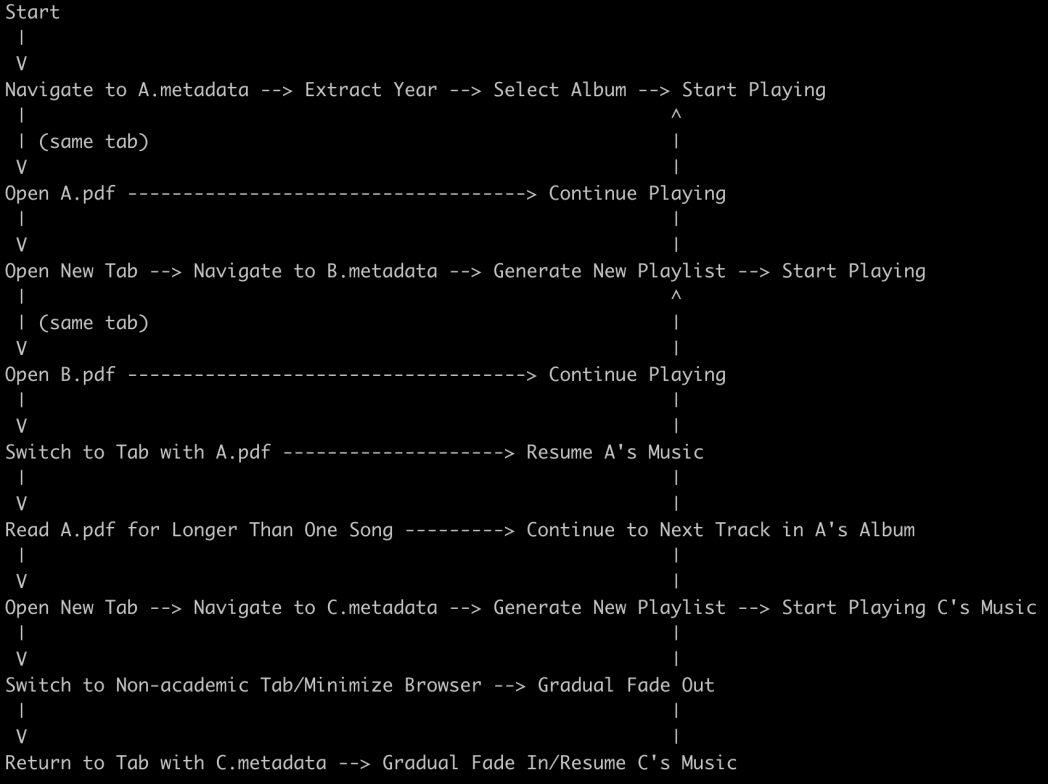
Reflecting back, this session was productive because I was familiar enough with UX design concepts to steer the conversation towards more depth. Out of curiosity, I started a new chat session with exactly the same UX consultant prompt as above but then played the part of a total novice instead of guiding it:
I don’t know anything about UX design. Can you help me get started since you are the expert?
The conversation that followed this prompt was far less useful since ChatGPT ended up giving me a basic primer on UX Design 101 and offering high-level suggestions for how I can start thinking about the user experience of Swift Papers. I didn’t want to nudge it too hard since I was pretending to be a novice, and it wasn’t proactive enough to ask me clarifying questions to probe deeper. Perhaps if I had prompted it to be more proactive at the start, then it could have elicited more information even from a novice.
This digression reinforces the widely-known consensus that what you get out of LLMs like ChatGPT is only as good as the prompts you’re able to put in. There’s all of this relevant knowledge hiding inside its neural network mastermind of billions and billions of LLM parameters, but it’s up to you to coax it into revealing what it knows by taking the lead in conversations and crafting the right prompts to direct it toward useful responses. Doing so requires a degree of expertise in the domain you’re asking about, so it’s something that beginners would likely struggle with.
The Last Big Hurdle: Working with the Spotify API
After ChatGPT helped me with UX design, the last hurdle I had to overcome was figuring out how to connect my Chrome extension to the Spotify Web API to select and play music. Like my earlier adventure with installing a date parsing library, connecting to web APIs is another common real-world programming task, so I wanted to see how well ChatGPT could help me with it.
The gold standard here is an expert human programmer who has a lot of experience with the Spotify API and who is good at teaching novices. ChatGPT was alright for getting me started but ultimately didn’t meet this standard. My experience here showed me that human experts still outperform the current version of ChatGPT along the following dimensions:
- Context, context, context: Since ChatGPT can’t “see” my screen, it lacks a lot of useful task context that a human expert sitting beside me would have. For instance, connecting to a web API requires a lot of “pointing-and-clicking” manual setup work that isn’t programming: I had to register for a paid Spotify Premium account to grant me API access, navigate through its web dashboard interface to create a new project, generate API keys and insert them into various places in my code, then register a URL where my app lives in order for authentication to work. But what URL do I use? Swift Papers is a Chrome extension running locally on my computer rather than online, so it doesn’t have a real URL. I later discovered that Chrome extensions export a fake chromiumapp.org URL that can be used for web API authentication. A human expert who is pair programming with me would know all these ultra-specific idiosyncrasies and guide me through pointing-and-clicking on the various dashboards to put all the API keys and URLs in the right places. In contrast, since ChatGPT can’t see this context, I have to explicitly tell it what I want at each step. And since this setup process was so new to me, I had a hard time thinking about how to phrase my questions. A human expert would be able to see me struggling and step in to offer proactive assistance for getting me unstuck.
- Bird’s-eye view: A human expert would also understand what I’m trying to do—selecting and playing date-appropriate songs—and guide me on how to navigate the labyrinth of the sprawling Spotify API in order to do it. In contrast, ChatGPT doesn’t seem to have as much of a bird’s-eye view, so it eagerly barrels ahead to generate code with specific low-level API calls whenever I ask it something. I, too, am eager to follow its lead since it sounds so confident each time it suggests code along with a convincing explanation (LLMs tend to adopt an overconfident tone, even if their responses may be factually inaccurate). That sometimes leads me on a wild goose chase down one direction only to realize that it’s a dead-end and that I have to backtrack. More generally, it seems hard for novices to learn programming in this piecemeal way by churning through one ChatGPT response after another rather than having more structured guidance from a human expert.
- Tacit (unwritten) knowledge: The Spotify API is meant to control an already-open Spotify player (e.g., the web player or a dedicated app), not to directly play songs. Thus, ChatGPT told me it was not possible to use it to play songs in the current browser tab, which Swift Papers needed to do. I wanted to verify this for myself, so I went back to “old-school” searching the web, reading docs, and looking for example code online. I found that there was conflicting and unreliable information about whether it’s even possible to do this. And since ChatGPT is trained on text from the internet, if that text doesn’t contain high-quality information about a topic, then ChatGPT won’t work well for it either. In contrast, a human expert can draw upon their vast store of experience from working with the Spotify API in order to teach me tricks that aren’t well-documented online. In this case, I eventually figured out a hack to get playback working by forcing a Spotify web player to open in a new browser tab, using a super-obscure and not-well-documented API call to make that player ‘active’ (or else it sometimes won’t respond to requests to play … that took me forever to figure out, and ChatGPT kept giving me inconsistent responses that didn’t work), and then playing music within that background tab. I feel that humans are still better than LLMs at coming up with these sorts of hacks since there aren’t readily-available online resources to document them. A lot of this hard-earned knowledge is tacit and not written down anywhere, so LLMs can’t be trained on it.
- Lookahead: Lastly, even in instances when ChatGPT could help out by generating good-quality code, I often had to manually update other source code files to make them compatible with the new code that ChatGPT was giving me. For instance, when it suggested an update to a JavaScript file to call a specific Chrome extension API function, I also had to modify my manifest.json to grant an additional permission before that function call could work (bitten by permissions again!). If I didn’t know to do that, then I would see some mysterious error message pop up, paste it into ChatGPT, and it would sometimes give me a way to fix it. Just like earlier, ChatGPT “knows” the answer here, but I must ask it the right question at every step along the way, which can get exhausting. This is especially a problem for novices since we often don’t know what we don’t know, so we don’t know what to even ask for in the first place! In contrast, a human expert who is helping me would be able to “look ahead” a few steps based on their experience and tell me what other files I need to edit ahead of time so I don’t get bitten by these bugs in the first place.
In the end I got this Spotify API setup working by doing some old-fashioned web searching to supplement my ChatGPT conversation. (I did try the ChatGPT + Bing web search plugin for a bit, but it was slow and didn’t produce useful results, so I couldn’t tolerate it any more and just shut it off.) The breakthrough came as I was browsing a GitHub repository of Spotify Web API example code. I saw an example for Node.js that seemed to do what I wanted, so I copy-pasted that code snippet into ChatGPT and told it to adapt the example for my Swift Papers app (which isn’t using Node.js):
Here’s some example code using Implicit Grant Flow from Spotify’s documentation, which is for a Node.js app. Can you adapt it to fit my chrome extension? [I pasted the code snippet here]
ChatGPT did a good job at “translating” that example into my context, which was exactly what I needed at the moment to get unstuck. The code it generated wasn’t perfect, but it was enough to start me down a promising path that would eventually lead me to get the Spotify API working for Swift Papers. Reflecting back, I later realized that I had manually done a simple form of RAG (Retrieval Augmented Generation) here by using my intuition to retrieve a small but highly-relevant snippet of example code from the vast universe of all code on the internet and then asking a super-specific question about it. (However, I’m not sure a beginner would be able to scour the web to find such a relevant piece of example code like I did, so they would probably still be stuck at this step because ChatGPT alone wasn’t able to generate working code without this extra push from me.)
Epilogue: What Now?
I have a confession: I didn’t end up finishing Swift Papers. Since this was a hobby project, I stopped working on it after about two weeks when my day-job got more busy. However, I still felt like I completed the initial hard parts and got a sense of how ChatGPT could (and couldn’t) help me along the way. To recap, this involved:
- Setting up a basic Chrome extension and familiarizing myself with the concepts, permission settings, configuration files, and code components that must coordinate together to make it all work.
- Installing third-party JavaScript libraries (such as a date parsing library) and configuring the npm and webpack toolchain so that these libraries work with Chrome extensions, especially given the strict security policies of Manifest v3.
- Connecting to the Spotify Web API in such a way to support the kinds of user interactions that I needed in Swift Papers and dealing with the idiosyncrasies of accessing this API via a Chrome extension.
- Sketching out detailed UX journeys for the kinds of user interactions to support and how Swift Papers can handle various edge cases.
After laying this groundwork, I was able to start getting into the flow of an edit-run-debug cycle where I knew exactly where to add code to implement a new feature, how to run it to assess whether it did what I intended, and how to debug. So even though I stopped working on this project due to lack of time, I got far enough to see how completing Swift Papers would be “just a matter of programming.” Note that I’m not trying to trivialize the challenges involved in programming, since I’ve done enough of it to know that the devil is in the details. But these coding-specific details are exactly where AI tools like ChatGPT and GitHub Copilot shine! So even if I had continued adding features throughout the coming weeks, I don’t feel like I would’ve gotten any insights about AI tools that differ from what many others have already written about. That’s because once the software environment has been set up (e.g., libraries, frameworks, build systems, permissions, API authentication keys, and other plumbing to hook things together), then the task at hand reduces to a self-contained and well-defined programming problem, which AI tools excel at.
In sum, my goal in writing this article was to share my experiences using ChatGPT for the more open-ended tasks that came before my project turned into “just a matter of programming.” Now, some may argue that this isn’t “real” programming since it feels like just a bunch of mundane setup and configuration work. But I believe that if “real-world” programming means creating something realistic with code, then “real-real-world” programming (the title of this article!) encompasses all these tedious and idiosyncratic errands that are necessary before any real programming can begin. And from what I’ve experienced so far, this sort of work isn’t something humans can fully outsource to AI tools yet. Long story short, someone today can’t just give AI a high-level description of Swift Papers and have a robust piece of software magically pop out the other end. I’m sure people are now working on the next generation of AI that can bring us closer to this goal (e.g., much longer context windows with Claude 2 and retrieval augmented generation with Cody), so I’m excited to see what’s in store. Perhaps future AI tool developers could use Swift Papers as a benchmark to assess how well their tool performs on an example real-real-world programming task. Right now, widely-used benchmarks for AI code generation (e.g., HumanEval, MBPP) consist of small self-contained tasks that appear in introductory classes, coding interviews, or programming competitions. We need more end-to-end, real-world benchmarks to drive improvements in these AI tools.
Lastly, switching gears a bit, I also want to think more in the future about how AI tools can teach novices the skills they need to create realistic software projects like Swift Papers rather than doing all the implementation work for them. At present, ChatGPT and Copilot are reasonably good “doers” but not nearly as good at being teachers. This is unsurprising since they were designed to carry out instructions like a good assistant would, not to be an effective teacher who provides pedagogically-meaningful guidance. With the proper prompting and fine-tuning, I’m sure they can do much better here, and organizations like Khan Academy are already customizing GPT-4 to become a personalized tutor. I’m excited to see how things progress in this fast-moving space in the coming months and years. In the meantime, for more thoughts about AI coding tools in education, check out this other recent Radar article that I co-authored, Teaching Programming in the Age of ChatGPT, which summarizes our research paper about this topic.