A case for managed and model-less inference serving Yadwadkar et al., HotOS’19
HotOS’19 is presenting me with something of a problem as there are so many interesting looking papers in the proceedings this year it’s going to be hard to cover them all! As a transition from the SysML papers we’ve been looking at recently, I’ve chosen a HotOS position paper from the Stanford Platform Lab to kick things off. As we saw with the SOAP paper last time out, even with a fixed model variant and hardware there are a lot of different ways to map a training workload over the available hardware. In “A case for managed and model-less inference serving” Yadwadkar et al. look at a similar universe of possibilities for model serving at inference time, and conclude that it’s too much to expect users to navigate this by themselves.
Making queries to an inference engine has many of the same throughput, latency, and cost considerations as making queries to a datastore, and more and more applications are coming to depend on such queries. “For instance, Facebook applications issue tens-of-trillions of inference queries per day with varying performance, accuracy, and cost constraints.”
If we want an increasing number of applications to use machine learning, we must automate issues that affect ease-of-use, performance, and cost efficiency for users and providers… Despite significant research, this is missing right now.
Perhaps inspired by serverless in spirit and in terminology, the path forward proposed in this paper is towards a managed and model-less inference serving system. Managed here means that the system automates resource provisioning for models to match a set of SLO constraints (cf. autoscaling). Model-less is more confusing. First off there still is a model of course (but then there are servers hiding behind a serverless abstraction too!). Most of the discussion in the paper focuses on model families, i.e. selecting among variants of a given model transparently to the end user. But the vision clearly seems to include selection of the model itself. I get the former, but the latter feels to me much more like something you’d be doing during model development and training rather than dynamically at inference time. Perhaps we are intended to develop and train multiple models with differing characteristics, and make all of these available to the inference serving system to dynamically select from at runtime?? The paper is silent on this issue.
… we argue for an interface to the managed inference serving system where users are able to focus on querying an inference for their tasks without needing to think of models, and the trade-offs offered by model-variants. We term this interface model-less.
Usability expectations
Creating a managed and model-less inferencing platform faces many challenges: applications have diverse SLOs (e.g. throughput sensitive vs latency sensitive); query patterns change dynamically over time; the underlying available hardware resources are diverse and also change over time; and their are many possible variants of a given model to choose from.
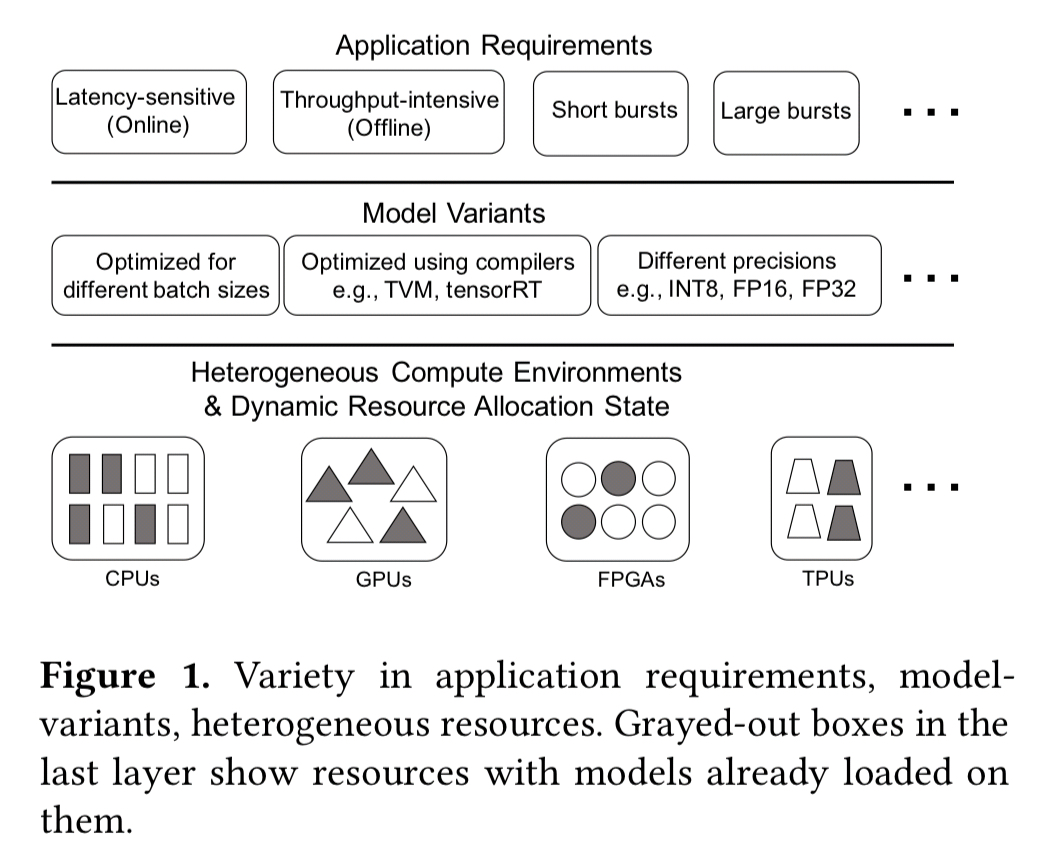
Model variants can be created by methods such as model compression, knowledge distillation, tuning of hyperparameter values, varying precision, optimising for different batch sizes, and so on. The following figure highlights how just one of these variables, batch size, impacts throughput and latency on ResNet50.
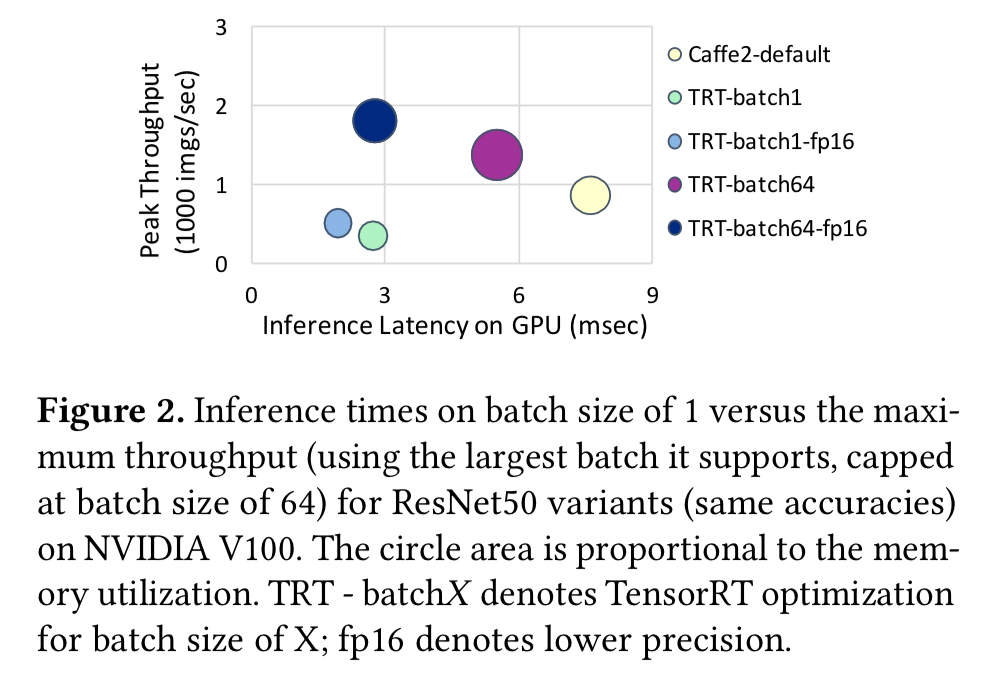
Expectation 1: Model-variant selection should be hidden behind a high-level API that allows users to simply specify their performance and cost objectives.
Different hardware architectures (CPUs, GPUs, TPUs, FPGAs, ASICs, …) offer different performance and cost trade-offs. Performance may vary by up to a couple of orders of magnitude for example.
Expectation 2: The choice of hardware should be hidden behind the same high level API for users. The system should select the right hardware type(s) to use at any point in time for meeting performance and cost SLOs.
We’d like to pack models as efficiently as possible on the underlying infrastructure. Different applications will have different needs (and resource requirements) in terms of throughput and latency. Today it is most common to provision separate resources for each model, but model multi-tenancy would allow us to make better use of the underlying resources. An evaluation conducted by the authors showed that most models experience minimal performance loss with up to 5-6 concurrent instances running on a shared GPU.
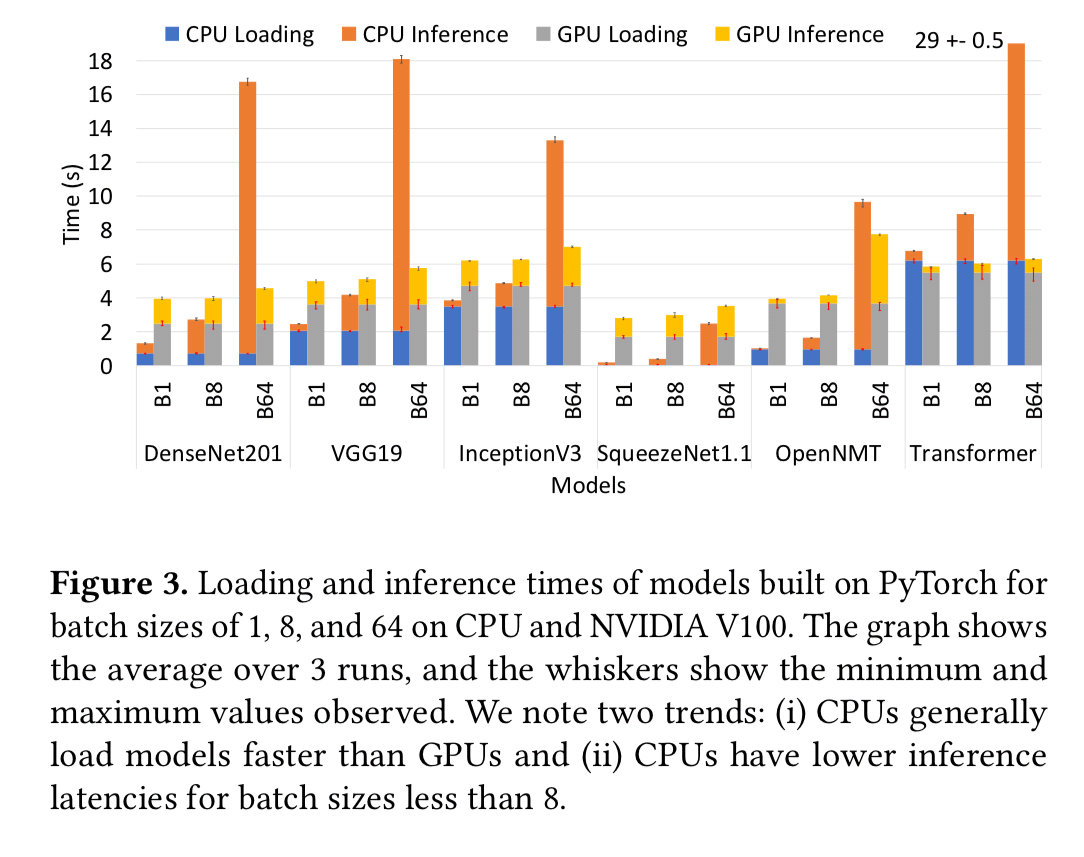
A quick back-of-the-envelope calculation suggests cost savings around an order of magnitude or more from sharing of hardware resources.
Expectation 3: Resource management to meet query cost and performance goals for different models under varying load should be abstracted away from users. To improve provider resource utilization and TCO, the system must transparently (i) share resources across different model instances, (ii) share models across users, and (iii) manage memory by replicating and evicting models based on observed load and popularity.
Similar to the start-up latency of a cold function in the serverless world, there’s start-up latency to be considered when first loading a model onto a given hardware platform. We pay this price when scaling up and when adding a new model to the system. Ideally we’d hide this from the user as best as possible:
Expectation 4: Start-up latency arising due to (i) loading a model-variant into the target hardware’s memory or storage and (ii) building an optimized model-variant, should be handled transparently.
Keeping all model-variants warm all the time though is going to be very expensive, so there’s a constraint:
Expectation 5: To prevent poor resource utilization, providers should not need to constantly keep model-variants running.
How can we get there?
The wonderful thing about position papers is that you don’t have to show working implementations ;). Section 3 of the paper instead provides a sketch of approaches and research directions that can take us towards the vision.
A user sends one or more queries for a prediction task, such as object recognition, with optional SLO constraints, for instance, 90 th percentile inference latency. The serving system takes care of the rest – automatic model-variant and target hardware selection, automatic model-variant generation, load-aware adaptive scaling, fault tolerance, monitoring, logging, maintaining security and privacy of models and queries.
Based on the SLO of a query, and the dynamic state of the system, it will be mapped to a pairing of a model variant and target hardware for running that variant. Model variants can be generated on demand if needed. Ideally there would already be an instance of the variant running on the target hardware, if not we’ll need to start one (presumably the start-up latency cost will be a factor in determining placement). “How to design mechanisms and policies to avoid or reduce this latency remains an open question.” It’s probably a combination of heuristics and learned behaviour to proactively launch variants, together with an eviction model to clean-up under-utilised model instances.
Further opportunities come from considering model placement at the edge and middle tiers, not just in cloud datacenters.
Different layers offer trade-offs in terms of resource capacity, cost and network latency, management overheads, and energy-efficiency. Utilizing the resources across this continuum of core-middle-edge computing opens new opportunities and research directions.
The final discussion in the paper concerns security and privacy. Authentication and authorization should be in place to prevent unauthorized access to queries, their submission patterns, and inference outcomes, to other users and providers. When building personalized models by adding a user-specific layer on top of a number of generic layers, can we share the generic layers across users? Are there privacy concerns in doing so?
The last word
The growing importance of ML inference forces us to finally solve several problems together: management of heterogeneity for both hardware and models, designing user interfaces, and building SLO-driven systems. These challenges are non-trivial and create new avenues for research. The good news, however, is that it is a bounded problem (i.e., models and model-variants are immutable once created), thus giving us hope to get it right soon.
Replace ‘model’ with ‘datastore’ and you’ll see a very similar set of problems that we’ve been chipping away at for a very long time. Hope that we can make meaningful progress soon, yes. But hope that we can ‘get it right’ soon and put this challenge behind us? My personal bet is that this is a longer road…