From Distributed Caches to Real-Time Digital Twins
Going back to the mid-1990s, online systems have seen relentless, explosive growth in usage, driven by ecommerce, mobile applications, and more recently, IoT. The pace of these changes has made it challenging for server-based infrastructures to manage fast-growing populations of users and data sources while maintaining fast response times. For more than two decades, the answer to this challenge has proven to be a technology called in-memory computing.
In general terms, in-memory computing refers to the related concepts of (a) storing fast-changing data in primary memory instead of in secondary storage and (b) employing scalable computing techniques to distribute a workload across a cluster of servers. Assuming bottlenecks are avoided, this enables transparent throughput scaling that matches an increase in workload, which in turn keeps response times low for users. It can also take advantage of the elastic computing resources available in cloud infrastructures to quickly and cost-effectively scale throughput to meet changes in demand.
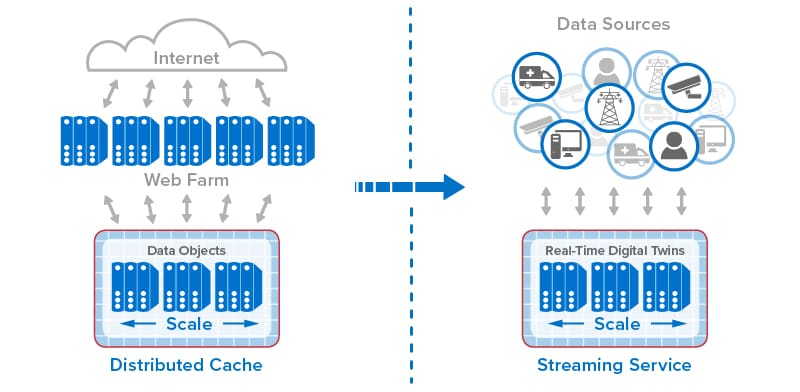
Harnessing the power of in-memory computing requires software platforms that can make in-memory computing’s scalability readily available to applications using APIs while hiding the complexity of its implementation. Emerging in the early 2000s, the first such platforms provided distributed caching on clustered servers with straightforward APIs for storing and retrieving in-memory objects. When first introduced, distributed caching offered a breakthrough for applications by storing fast-changing data in memory on a server cluster for consistently fast response times, while simultaneously offloading database servers that would otherwise become bottlenecked. For example, ecommerce applications adopted distributed caching to store session-state, shopping carts, product descriptions, and other data that shoppers need to be able to access quickly.
Software platforms for distributed caching, such as ScaleOut StateServer®, which was introduced in 2005, hide internal mechanisms for cluster membership, throughput scaling, and high availability to take full advantage of the cluster’s scalable memory without adding complexity to applications. They transparently distribute stored objects across the cluster’s servers and ensure that data is not lost if a server or network component fails.
As distributed caching has evolved over the last two decades, additional mechanisms for in-memory computing have been incorporated to take advantage of the computing power available in the server cluster. Parallel query enables stored objects on all servers to be scanned simultaneously to retrieve objects with desired properties. Data-parallel computing analyzes objects on the server cluster to extract and report patterns of interest; it scales much better than parallel query by avoiding network bottlenecks and by using the cluster’s computing resources.
Most recently, stream-processing has been implemented with in-memory computing to simultaneously analyze telemetry from thousands or even millions of data sources and track dynamic state information for each data source. ScaleOut Software’s real-time digital twin model provides straightforward APIs for implementing stream-processing applications within its ScaleOut Digital Twin Streaming Service™, an Azure-based cloud service, while hiding internal mechanisms, such as distributing incoming messages to in-memory objects, updating state information for each data source, and running aggregate analytics.
The following diagram shows the evolution of in-memory computing from distributed caching to stream-processing with real-time digital twins. Each step in the evolution has built on the previous one to add new capabilities that take advantage of the scalable computing power and fast data access that in-memory computing enables.
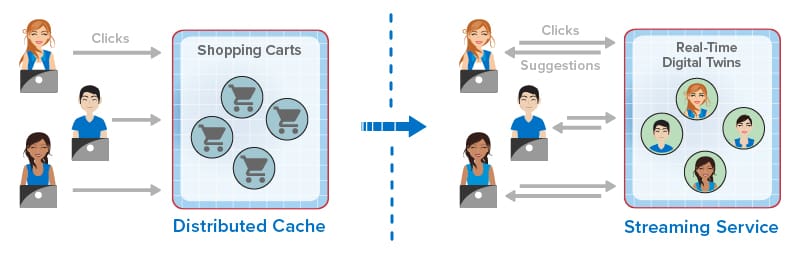
For ecommerce applications, this evolution has created new capabilities that dramatically improve the experience for online shoppers. Instead of just passively hosting session-state and shopping carts, online applications now can mine shopping carts for dynamic trends to evaluate the effectiveness of product descriptions and marketing programs (such as flash sales). They can also employ real-time digital twins or similar techniques to track each shopper’s behavior and make recommendations. By analyzing a click-stream of product selections in the context of knowledge of a shopper’s preferences and demographics, an ecommerce site can make highly focused recommendations to assist the shopper.
For example, one of ScaleOut Software’s customers recently upgraded from just using distributed caching to scale its ecommerce application. This customer now incorporates stream-processing capabilities using ScaleOut StreamServer® to capture click-streams and score users so that its web site can make more effective real-time offers.
The following diagram illustrates how the evolution of in-memory computing has enhanced the online experience for ecommerce shoppers by providing in-the-moment suggestions:
Starting with its development for parallel supercomputing in the late 1990s and evolving into its latest form as a cloud-based service, in-memory computing has offered powerful, software based APIs for building applications that serve large populations of users and data sources. It has helped assure that these applications deliver predictably fast performance and scale to meet the demands of growing workloads. In the next few years, we should continued innovation from in-memory computing to help ecommerce and other applications maintain their competitive edge.