

SLOs done right: how DevOps teams can build better service-level objectives
Dynatrace
MARCH 16, 2023
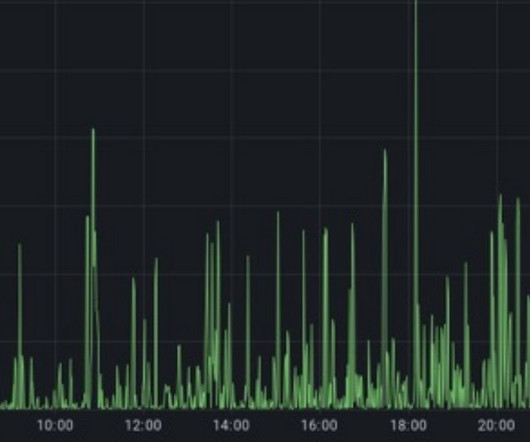
So how do development and operations (DevOps) teams and site reliability engineers (SREs) distinguish among good, great, and suboptimal SLOs? The state of service-level objectives While SLOs play a critical role in helping DevOps and SRE teams align technical objectives with business goals, they’re not always easy to define.














































Let's personalize your content