
Architectural Insights: Designing Efficient Multi-Layered Caching With Instagram Example
DZone
FEBRUARY 27, 2024
Leveraging this hierarchical structure can significantly reduce latency and improve overall performance.

DZone
FEBRUARY 27, 2024
Leveraging this hierarchical structure can significantly reduce latency and improve overall performance.

DZone
JUNE 22, 2023
It involves a combination of techniques and best practices aimed at reducing latency, improving user experience, and increasing the overall efficiency of the system. API performance optimization is the process of improving the speed, scalability, and reliability of APIs.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
The Netflix TechBlog
SEPTEMBER 29, 2022
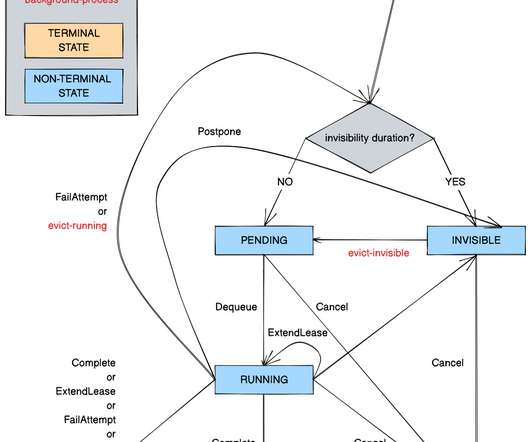
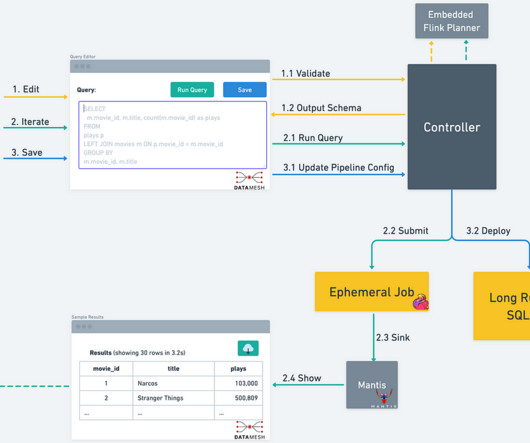
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform. Over the past 2.5

The Netflix TechBlog
SEPTEMBER 3, 2021
Remote calls are never free; they impose extra latency, increase probability of an error, and consume network bandwidth. How can we achieve a similar functionality when designing our gRPC APIs? This (alongside some other techniques like ZigZag encoding for signed types) makes protobuf messages space-efficient.

Scalegrid
JANUARY 25, 2024
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. These essential data points heavily influence both stability and efficiency within the system.

Scalegrid
MARCH 28, 2024
Redis Data Types and Structures The design of Redis’s data structures emphasizes versatility. Snapshots provide point-in-time captures of the dataset, which are efficient for recovery on startup. It is designed to cache plain text values, offering fast read and write access to frequently accessed data.

The Netflix TechBlog
JANUARY 10, 2024
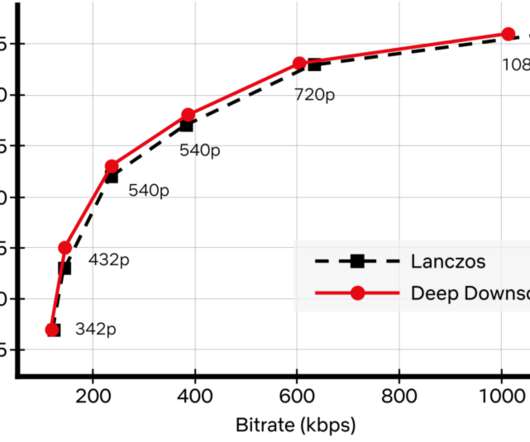
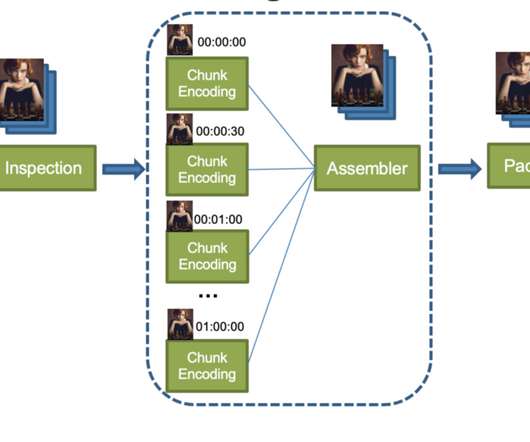
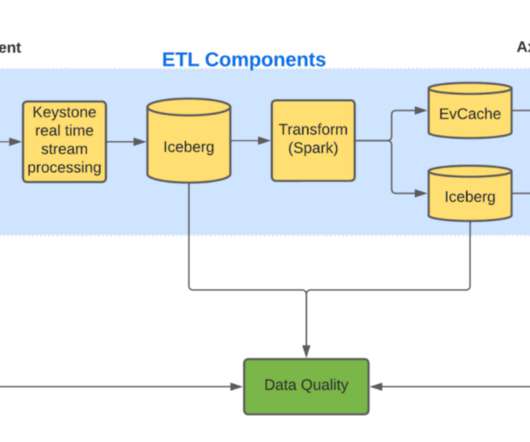
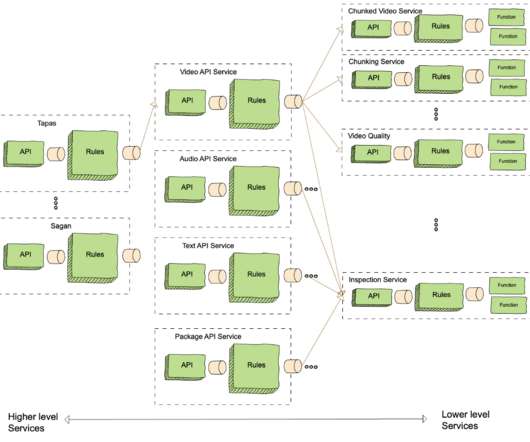
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.

Expert insights. Personalized for you.



































Let's personalize your content