


Rebuilding Netflix Video Processing Pipeline with Microservices
The Netflix TechBlog
JANUARY 10, 2024
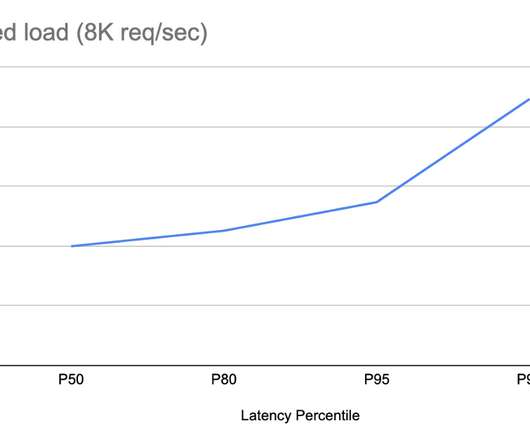
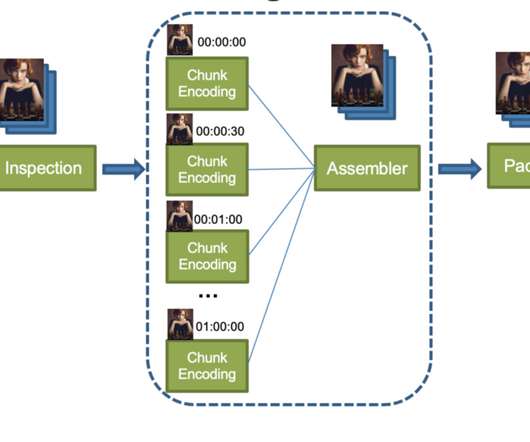
This introductory blog focuses on an overview of our journey. Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. This architecture shift greatly reduced the processing latency and increased system resiliency. divide the input video into small chunks 2.








































Let's personalize your content