
Batch Processing for Data Integration
DZone
NOVEMBER 7, 2023
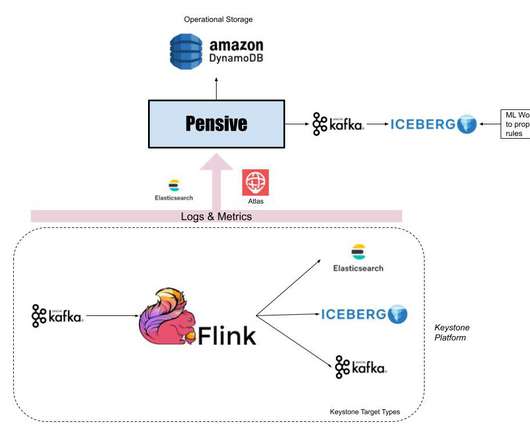
In the labyrinth of data-driven architectures, the challenge of data integration—fusing data from disparate sources into a coherent, usable form — stands as one of the cornerstones. As businesses amass data at an unprecedented pace, the question of how to integrate this data effectively comes to the fore.






































Let's personalize your content