
What are quality gates? How to use quality gates to deliver better software at speed and scale
Dynatrace
FEBRUARY 21, 2024
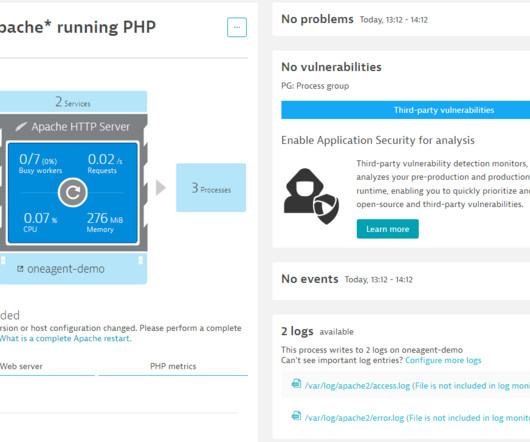
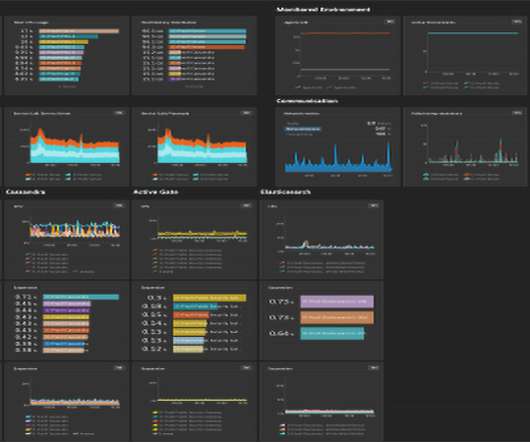
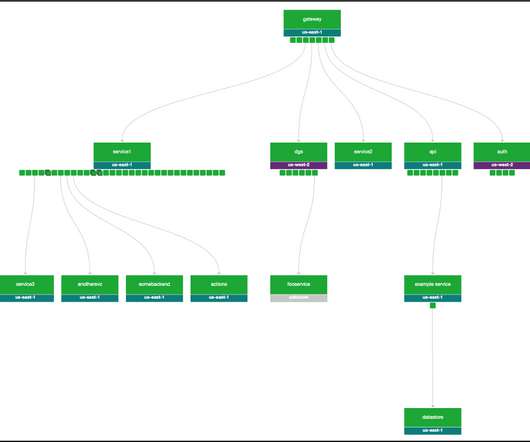
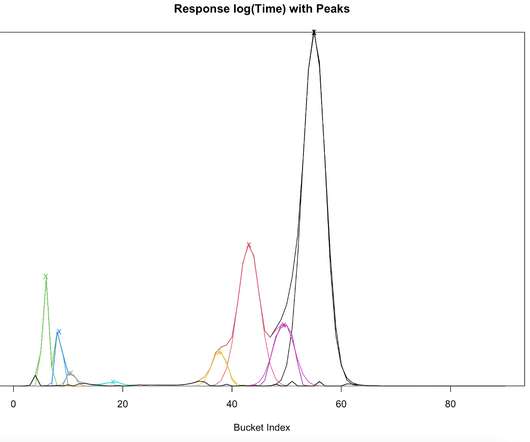
To remain competitive in today’s fast-paced market, organizations must not only ensure that their digital infrastructure is functioning optimally but also that software deployments and updates are delivered rapidly and consistently. In this example, unlike latency, the remaining three signals did not receive a “pass.”







































Let's personalize your content